Themen für Abschlussarbeiten
Folgende Themen können bei mir als Abschlussarbeit im Bereich Mathematik/Informatik bearbeitet werden. Weitere Themen sind nach Absprache möglich.
Spannbaumbasierte Dimensionsreduktion
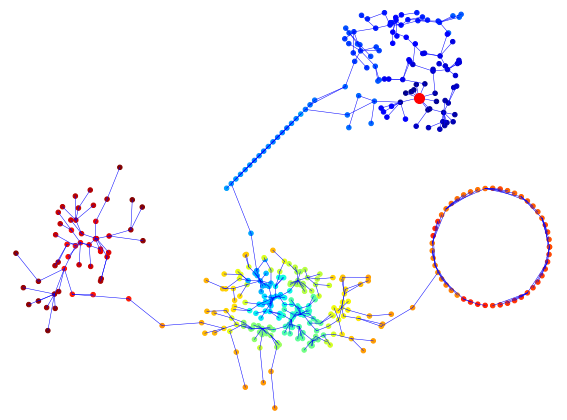
Das OPTICS-Verfahren für das Clustering erstellt als Nebenprodukt einen Spannbaum der betrachtenen Datenmenge. Dieser kann zur Dimensionsreduktion in visualisierbare Räume (2D oder 3D) genutzt werden indem die Kantenlängen gerade den Abständen der Datenpunkte im ursprünglichen Datenraum entsprechen. Wesentlich dafür ist die überschneidungsfreie Darstellung des Spannbaums in niedrigen Dimensionen.
Im Rahmen der Abschlussarbeit sollen Verfahren zur Darstellung von Graphen (insbesondere Spannbäumen) recherchiert werden. Aus den gewonnenen Erkenntnisssen und ggf. eigenen Überlegungen soll ein Algorithmus entwickelt werden, der einen Spannbaum mit vorgegebenen Kantenlängen überschneidungsfrei in der Ebene anordnet. Unter allen möglichen Anordnungen soll eine möglichst übersichtliche gefunden werden.
Schwerpunkte: Literaturrecherche, Algorithmenentwicklung
Schichtweises Training neuronaler Netze
Üblicherweise werden künstliche neuronale Netze als Ganzes trainiert. Dabei ist die Konvergenz des Optimierungsverfahrens ungewiss und langsam. In der Literatur existieren verschiedenen Ansätze geschichtete neuronale Netze schichtweise zu trainieren, sodass einerseits der Trainingsaufwand sinkt und andererseits die Struktur des Optimierungsproblems handhabbarer wird. Solche Ansätze sind im Rahmen der Abschlussarbeit zu recherchieren und miteinander zu vergleichen.
Aufbauend auf den gewonnenen Erkenntnissen soll ein Verfahren implementiert und erprobt werden, welches beginnend mit einem einschichtigen Netz ein mehrschichtiges Netz Schicht für Schicht aufbaut und dabei stets nur die Gewichte der neuesten Schicht trainiert. Trainingserfolg und -geschwindigkeit sollen mit in der Literatur gefunden Verfahren und mit Standard-Trainingsverfahren verglichen werden.
Schwerpunkte: Literaturrecherche, Test und Vergleich von Algorithmen
Natives NaN-Handling
Die Daten für überwachte Lernaufgaben enthalten fast immer Fehlstellen (NaNs, NaN = Not a Number). Übliche Modelle des überwachten Lernens wie beispielsweise künstliche neuronale Netze können mit solchen Fehlstellen nicht umgehen. Deshalb werden Datensätze mit Fehlstellen wahlweise verworfen oder mittels statistischer Verfahren geschätzt (Imputation). Entweder gehen durch des Entfernen von Datensätzen unter Umständen relevante Informationen verloren oder durch das Füllen von Fehlstellen werden Informationen in die Datensätze eingebracht, die eventuell nicht korrekt sind.
Im Rahmen einer Abschlussarbeit sollen Ansätze für natives NaN-Handling recherchiert, erdacht und getestet werden. Beispielsweise könnten zusätzliche binäre Features die Verfügbarkeit von Werten der eigentlichen Features in jedem Datensatz kodieren und neuronale Netze und andere Modelle diese Information in der Trainingsphase geeignet einbeziehen.
Schwerpunkte: Literaturrecherche, Algorithmenentwicklung, Test und Vergleich von Algorithmen
Kleinste umschließende Kreise auf Kugeloberflächen
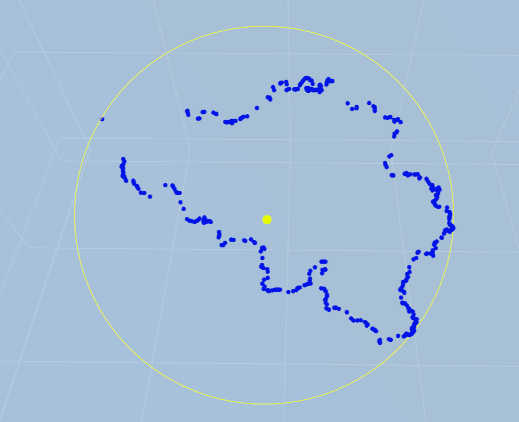
Für das Finden des kleinsten Kreises, der eine gegebenen Punktwolke in der Ebene umschließt gibt es seit Jahrzehnten hinreichend gute, insbesondere schnelle, Algorithmen. Der wichtigste ist der Algorithmus von Welzl. Vor allem für Anwendungen mit Geodaten müssen auch kleinste umschließende Kreise auf Kugeloberflächen effizient bestimmt werden. Hier gibt es noch keine vollständig befriedigende Lösung.
Der in A simple linear time algorithm for smallest enclosing circles on the (hemi)sphere vorgestellte Algorithmus kann das Problem auf Halbkugeln effizient lösen, jedoch nicht, wenn die Punktwolke mehr als eine Halbkugel bedeckt. Für diesen Vollkugel-Fall wird in der genannten Arbeit eine Lösung skizziert, die im Rahmen einer Bachelorarbeit vollständig ausgearbeitet und implementiert werden soll.
Schwerpunkte: Implementierung von Algorithmen, praxistaugliche Umsetzung als Python-Paket
Zuverlässigkeit von Wettervorhersagen
Die Steuerung vieler industrieller Prozesse hängt von den Wetterbedingungen ab. Je besser die Vorhersagen sind, desto präziser können die Steuerparameter gewählt, ggf. Energie gespart und Kosten gesenkt werden. Gute Wettervorhersagen sind insbesondere bei der Fernwärme- und Fernkälteversorgung von Wichtigkeit. Je zuverlässiger die Vorhersagen, desto geringer können die einzuplanenden Reserven und damit verbundene finanzielle Verluste sein. Aber wie zuverlässig sind Wettervorhersagen? Kann man die kurzfristige Zuverlässigkeit eventuell aus Änderungen in langfristigen Vorhersagen ableiten?
Basierend auf 10-Tage-Vorhersagen und Messwerten des Deutscher Wetterdienstes soll in der Abschlussarbeit die Zuverlässigkeit von 48-Stunden-Vorhersagen untersucht und ein Verfahren zum Schätzen der Zuverlässigkeit kurzfristiger Vorhersagen aus längerfristigen Vorhersagen, welche täglich 10 bis 3 Tage im Voraus veröffentlicht werden, entwickelt werden. Grob formuliert: Wenn die langfristigen Vorhersagen für einen Tag stark schwanken, können wir dann davon ausgehen, dass die kurzfristigen Vorhersagen für diesen Tag unzuverlässiger sind als bei konstanten langfristigen Vorhersagen?
Schwerpunkte: Datenanalyse, Python-Programmierung
Wettervorhersage auf Grundlage historischer Messwerte
Der Deutscher Wetterdienst bietet umfangreiche Messreihen von Wetterparametern hochaufgelöst über Jahrzehnte als Open-Data an. In Rahmen einer Abschlussarbeit soll das Wetter der zurückliegenden Tage mit historischen Messwerten verglichen werden um Zeiträume mit ähnlichem Wetterverlauf zu finden. Die weitere Wetterentwicklung in den gefundenen Zeiträumen kann dann als Grundlage für die Vorhersage des aktuellen Wettergeschehens dienen. So könnten Wettervorhersagen ohne aufwendige Technik wie z.B. Satelliten entstehen. Auch können so Unsicherheiten bezüglich der weiteren Wetterentwicklung abgeschätzt werden.
Schwerpunkte: Datenanalyse, Python-Programmierung, Visualisierung