Häufigkeiten und Histogramme in R#
Hier schauen wir uns an, wie man Häufigkeiten zu einer Stichprobe bestimmt und Histogramme zu einer Stichprobe ausgibt.
Eingabe der Stichprobe#
Hier wird eine Stichprobe als numerischer Vektor eingegeben. Die Werte können beliebig angepasst werden. Wir speichern die Stichprobe unter dem Namen stichprobe.
stichprobe <- c(2,4,4,4,7,5,4,6,8,4,5,7,4,8,2,6,6,4,4,3)
Stichprobengröße auslesen#
Die Funktion length() gibt die Anzahl der Elemente im Vektor zurück, also die Stichprobengröße. Hier wird der Variablen n der Wert length(stichprobe) zugewiesen. In der nächsten Zeile wird R aufgefordert n auszugeben.
n <- length(stichprobe)
n
Absolute und relative Häufigkeiten berechnen#
Die Funktion table() zählt die Häufigkeit jedes Wertes in der Stichprobe. Mit prop.table() werden die relativen Häufigkeiten berechnet.
table(stichprobe)
table(stichprobe)/n
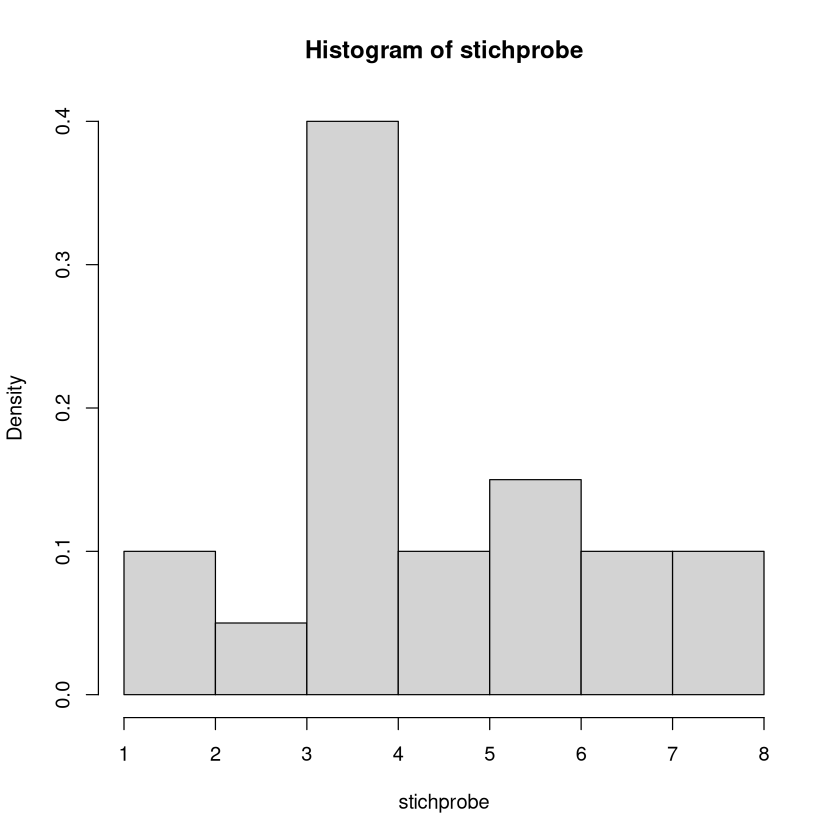
stichprobe
2 3 4 5 6 7 8
2 1 8 2 3 2 2
stichprobe
2 3 4 5 6 7 8
0.10 0.05 0.40 0.10 0.15 0.10 0.10
Oft führen mehrere Wege zum Ziel. Die relativen Häufigkeiten können wir auch mit dem Befehl prop.table() berechnen. Dann muss man als Argument aber nicht die Stichprobe, sondern table(stichprobe) eingeben.
# Alternative
absH <- table(stichprobe)
relH <- prop.table(absH)
absH
relH
stichprobe
2 3 4 5 6 7 8
2 1 8 2 3 2 2
stichprobe
2 3 4 5 6 7 8
0.10 0.05 0.40 0.10 0.15 0.10 0.10
Histogramme erstellen#
Um ein Histogramm zu erstellen gibt es verschiedene Möglichkeiten wir nutzen hier den Befehl hist() oder den Befehl barplot().
Histogramme mit hist()#
hist(stichprobe)
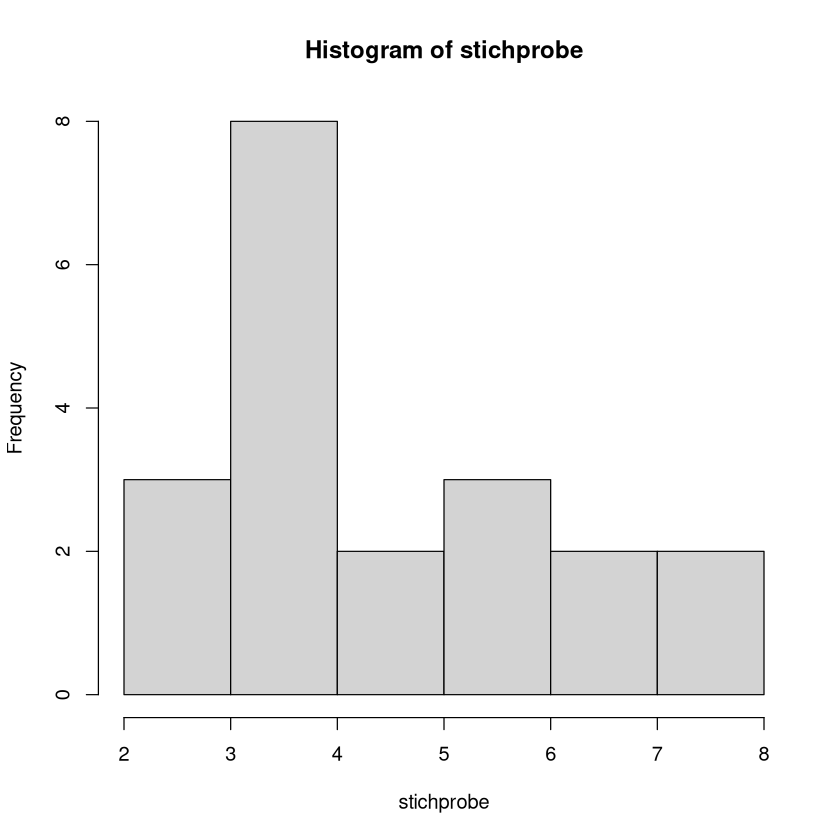
Seltsamerweise gibt es hier 6 Säulen und nicht 8, wie wir erwarten würden. Das Programm R fasst die Klassen manchmal selbstständig zusammen. Hier wurden z.B. die ersten beiden Ausprägungen (2 und 3) zusammen in einer Säule dargestellt. Das gefällt uns hier nicht. Wir wollen „erzwingen“, dass jeder Wert seine eigene Säule bekommt. Dazu nutzen wir das Argument breaks. Hier kann man einen Vektor angeben, in dem steht, nach welchen Werte R „unterbrechen“ soll. Alle Werte zwischen 2 breaks werden in eine Klasse genommen. Deren Häufigkeit wird dann in einer Säule dargestellt.
hist(stichprobe, breaks=c(1,2,3,4,5,6,7,8))
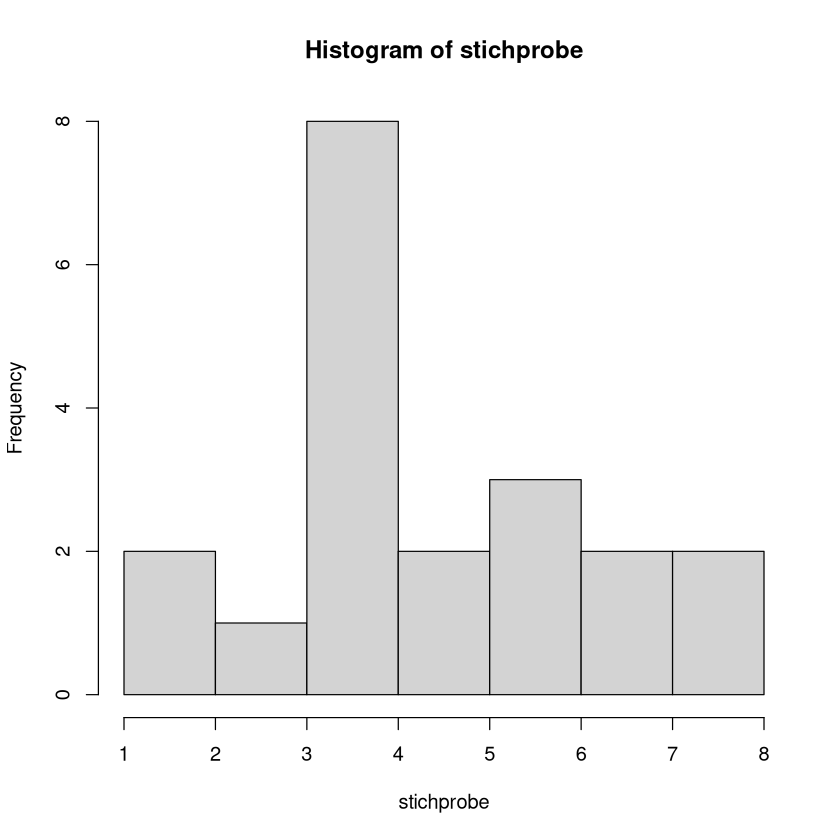
Man könnte auch die relative Häufigkeit plotten. Dazu fügt man im hist-Befehl das Argument probability=TRUE hinzu.
hist(stichprobe, breaks=c(1,2,3,4,5,6,7,8), probability = TRUE)
Wir wollen die Grafik noch etwas anpassen. Zum Beispiel soll der Titel und die Achsenbeschriftung geändert werden.
hist(stichprobe,
main="Wunderschönes Histogramm", # hier wird der Titel angepasst
xlab="Werte", # die Beschriftung der x-Achse
ylab="Häufigkeit", # die Beschriftung der y-Achse
col="lightgreen", # die Farbe der Säulen
labels=TRUE) # die Höhe der Säulen wird über den Säulen abgetragen
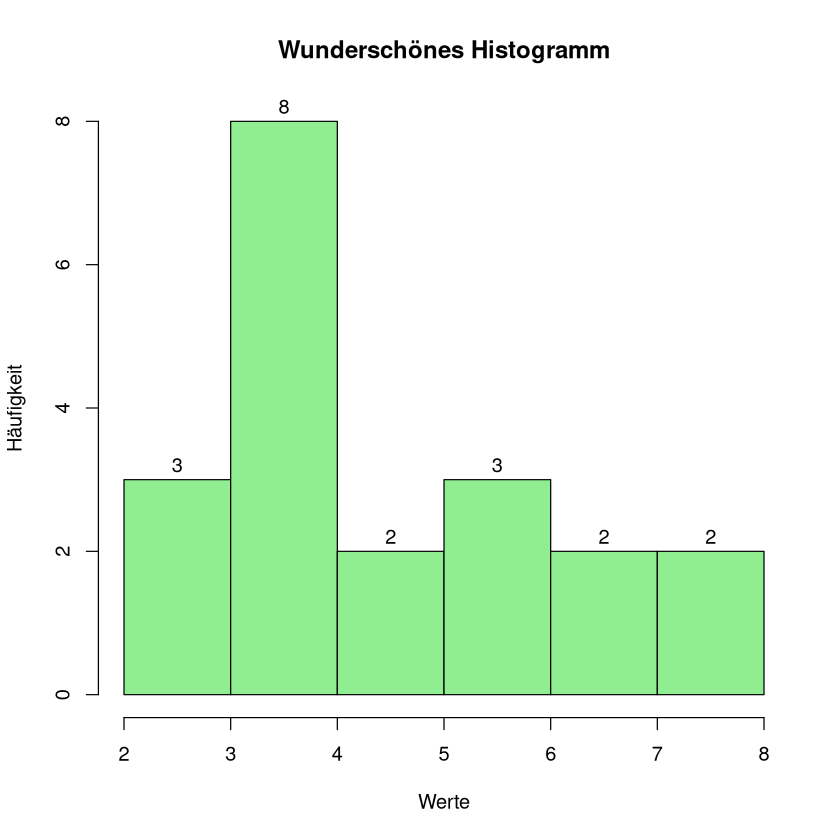
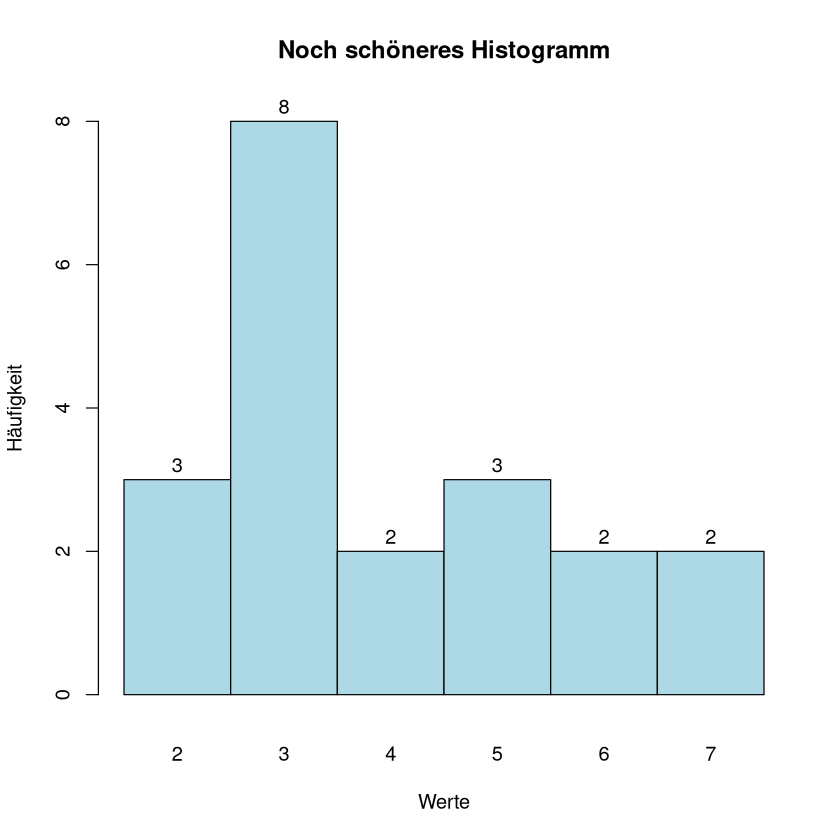
Nun soll die Beschriftung der Säulen mittig darunter stehen.
h<-hist(stichprobe, plot=FALSE) # Histgramm wird nicht geplottet sondern zunächst in Variable h geschrieben
plot(h, # hier kommt der Befehl zum Plot
xaxt="n", # zunächst keine Zahlen an der x-Achse
main="Noch schöneres Histogramm", # hier wird der Titel angepasst
xlab="Werte", # die Beschriftung der x-Achse
ylab="Häufigkeit", # die Beschriftung der y-Achse
col="lightblue", # die Farbe der Säulen
labels=TRUE) # die Höhe der Säulen wird über den Säulen abgetragen)
axis(1, # mit axis passen wir die x-Achse (1) an, eine (2) würde die y-Achse anpassen
h$mids, # h$mids ist der Vektor mit den Mitten der Säulen; dort wollen wir Werte eintragen
labels=floor(h$mids), # labels legt die Werte fest; hier sind es die abgerundeten "Mitten"
tick = FALSE) # keine ticks auf der x-Achse
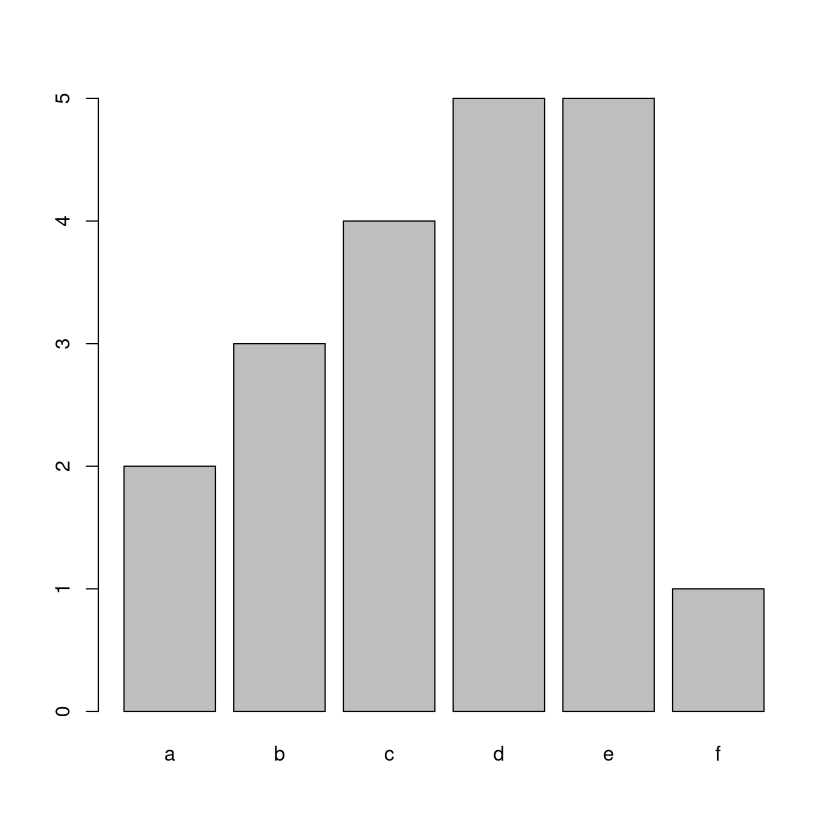
Histogramme mit barplot()#
Histogramme kann man auch mit dem Befehl barplot() erstellen
barplot(table(stichprobe))
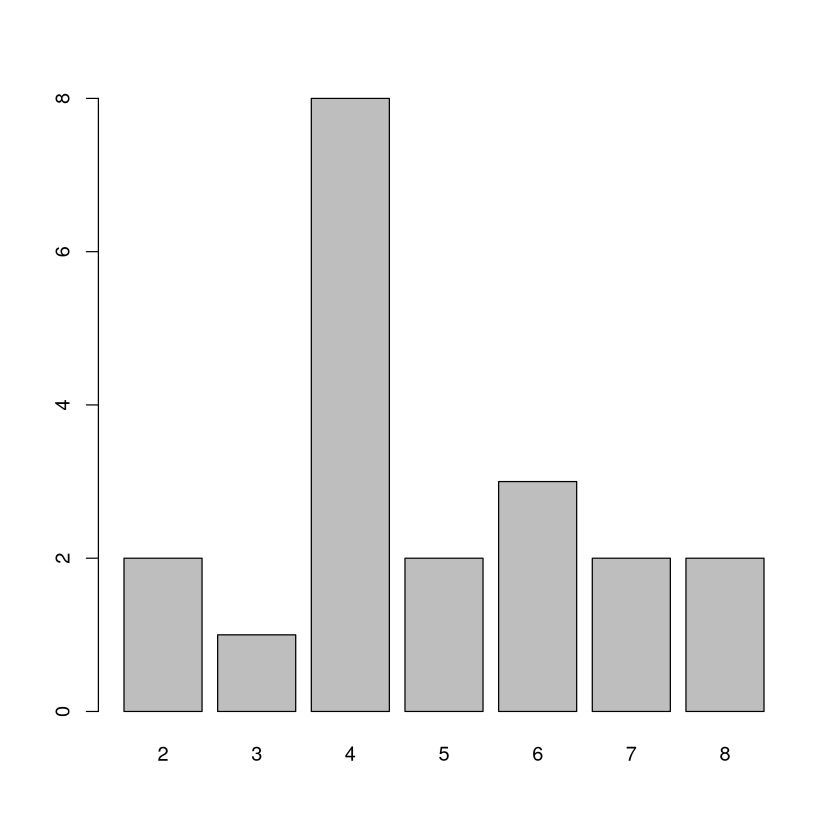
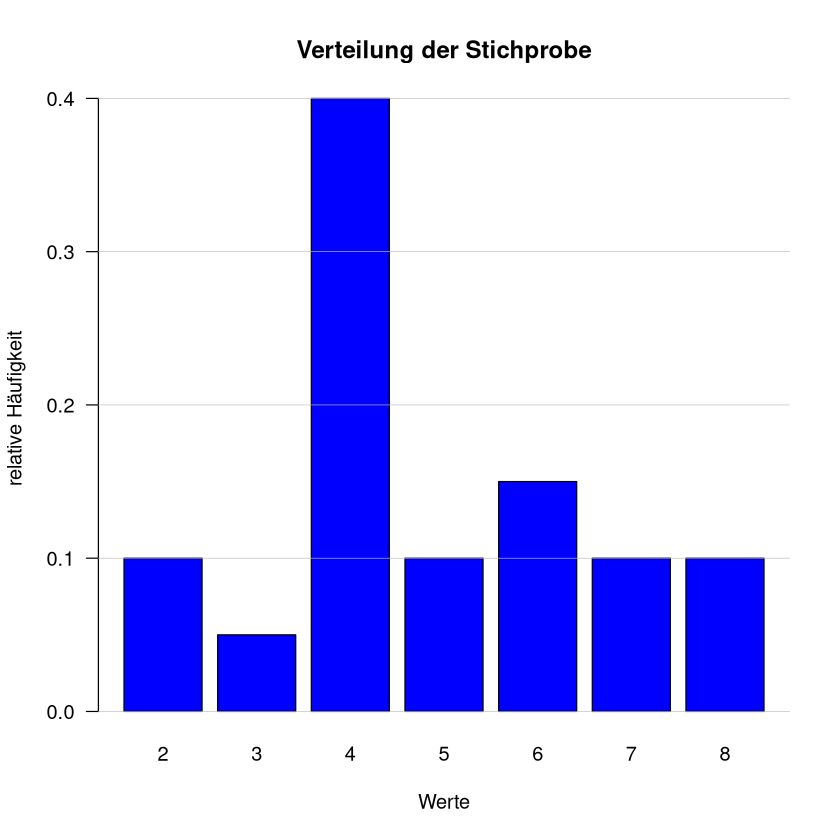
Das soll noch etwas hübscher werden:
# Erstelle eine Stichprobe
stichprobe <- c(2,4,4,4,7,5,4,6,8,4,5,7,4,8,2,6,6,4,4,3)
# Erstelle ein Histogramm
barplot(table(stichprobe)/length(stichprobe), # wir Teilen durch die Gesamtzahl -> relative Häufigkeit
main = "Verteilung der Stichprobe", # Titel
xlab = "Werte", # Beschriftung x-Achse
ylab = "relative Häufigkeit", # Beschriftung y-Achse
col = "blue", # Farbe der Balken
las = 1 # Ausrichung d. Beschriftung drehen
)
# Füge ein Gitter hinzu
grid(col = "gray", lty = 1, lwd = 0.5, nx= NA, ny=NULL)
Nominal messbare Daten#
Stichproben können auch Vektoren mit Buchstaben oder Wörtern sein. Dann ist es genau so leicht Häufigkeiten zu bestimmen.
stichprobe2 <- c("a","c","b","b","e","d","c","e","b","c","a","c","d","d","d","d","e","e","e","f")
table(stichprobe2)
table(stichprobe2)/length(stichprobe2)
stichprobe2
a b c d e f
2 3 4 5 5 1
stichprobe2
a b c d e f
0.10 0.15 0.20 0.25 0.25 0.05
Um Historgramme für solche Daten zu plotten funktioniert der Befehl hist() nicht. Jedoch klappt es mit barplot() wie gewohnt.
barplot(table(stichprobe2))