Die Computertomografie (CT) ist ein weit verbreitetes medizinisches und industrielles Bildgebungsverfahren. Diskutieren hier alle Teilschritte vom Hardware-Aufbau bis zum Lösungsalgorithmus. Schwerpunkt sind das Erkennen von zu lösenden (Teil-)Problemen, die Auswahl geeigneter Lösungsverfahren und deren Implementierung. Nicht betrachtet wird die Effizienz der Algorithmen, da die derzeit effizientesten Verfahren unsere mathematischen Fähigkeiten übersteigen.
5.1Funktionsweise¶
Grundidee:
Röntgenbilder aus vielen verschiedenen Richtungen aufnehmen.
Aus diesen Bildern Rückschlüsse auf die Strahlenabsorption im Inneren des Objekts schließen.
Dass man aus den Einzelbildern theoretisch das Innere des Objekts rekonstrukieren kann, ist seit 1917 bekannt (siehe Johann Radon und Radon-Transformation). Die technische Umsetzung benötigt aufgrund des Rechenaufwands einen Computer, sodass erst in den 1970er-Jahren erste CT-Geräte entwickelt wurden. Diese arbeiteten nach dem Parallelstrahlverfahren: Die Einzelbilder wurden schichtweise aufgenommen (also nur eine Rasterzeile jedes Bildes) und die Röntgenstrahlen liefen parallel durch das Objekt (vgl. Abbildung).

Funktionsprinzip der Computertomografie (links) und ein Sinogramm als Beispiel für die direkt gemessenen Daten, aus denen das Innere des untersuchten Objekts rekonstruiert werden soll (rechts).
Heute sind fächerförmige Strahlenverläufe üblich. Teils werden die Schichten auch überlappend aufgenommen oder man löst sich gänzlich vom schichtweisen Vorgehen, indem Röntgenquelle und Detektor spiralförmig um das Objekt bewegt werden (Spiral- oder Helix-CT).
5.2Modellierung¶
Das Innere des Objekts in einer Aufnahmeschicht sei durch eine stetige Funktion beschrieben, die nur im Inneren der Einheitskreisscheibe von Null verschieden ist. Der Wert beschreibt die Absorption von Röntgenstrahlen im Punkt des Objekts aufgrund des dort vorhandenen Gewebes/Materials.
Der Aufnahmevorgang wird durch die Radon-Transformation beschrieben. Diese bildet stetige Funktionen (wie oben) auf stetige Funktionen
ab, indem sie entlang parallel verlaufender Geraden integriert:
(IDVID 510, schöne Animation). Bezeichnen wir mit die vom Detekor zum durch beschriebenen Strahlverlauf gemessene Intensität, so gilt
wobei die Intensität der Röntgenquelle angibt (Lambert-beersches Gesetz). Wir erhalten also
für den Zusammenhang zwischen Messwerten und der gesuchten Funktion .
Die Radon-Transformation ist eine lineare Abbildung, kann also nach geeigneter Diskretisierung als Matrix-Vektor-Multiplikation umgesetzt werden.
Die Anforderungen an ein Modell sind allerdings nur teilweise erfüllt:
Zu gegebenen Daten findet man stets eine Lösung (eine mathematisch sauberere Formulierung übersteigt unsere Möglichkeiten).
Die Lösung ist eindeutig.
ABER: Die Lösung reagiert sehr empfindlich auf Änderungen in den Daten (Messfehler/Rauschen!).
Die unstetige Abhängigkeit der Lösung von den Daten ist kein (!) Modellierungsfehler, sondern in der Sache an sich begründet. Manche/viele Vorgänge in der Physik besitzen keine stetige Umkehrung. Wie wir mit dieser Situation umgehen, klären wir später.
Das Modell vernachlässigt diverse Details:
Die Strahlen werden nie exakt entlang paralleler Geraden verlaufen, sondern sich mit Entfernung von der Quelle etwas aufweiten.
Effekte wie Beugung, Brechung, Strahlaufhärtung werden nicht beachtet.
Das Objekt wird als starr angenommen, obwohl die Aufnahme ein gewisses Zeitintervall in Anspruch nimmt, in dem Bewegungen stattfinden können.
5.3Testdaten¶
Benötigen Daten (Sinogramm) zum Testen verschiedener Lösungsansätze.
Sind die Testdaten fehlerbehaftet, so ist nicht klar, ob Fehler in der Lösung aus unserem Lösungsansatz (bzw. dessen Implementierung) oder aus den Datenfehlern resultieren. Auch wenn später hochauflösende Daten verwendet werden sollen, sind für die zahlreichen Testläufe niedrig aufgelöste Daten unter Umständen sehr zeitsparend. Ohne Kenntnis der exakten Lösung können wir nicht beurteilen, ob unser Verfahren korrekt arbeitet.
Die obigen Anforderungen sind praktisch nur mit synthetischen Daten erfüllbar. Für die Computertomografie verwendet man gern das so genannte Shepp-Logan-Phantom, welches in The Fourier Reconstruction of a Head Section (Shepp, Logan 1974) eingeführt wurde. Dieses besteht aus einer Überlagerung von zehn verschieden großen Ellipsen. Der folgende Code erzeugt ein Rasterbild des Shepp-Logan-Phantoms aus den Ellipsen-Definitionen (IDVID 515). Die in der ursprünglichen Arbeit verwendeten Grauwerte haben zu geringen Kontrast für eine gut erkennbare Darstellung, sodass wir diese ersetzen mit den in The Radon Transform - Theory and Implementation (Toft, 1996) verwendeten Werten.
import numpy as np
import matplotlib.pyplot as plt
def ellipse_dict(x, y, angle, axis1, axis2, value):
return dict(x=x, y=y, angle=angle, axis1=axis1, axis2=axis2, value=value)
shepp_logan_data = [
ellipse_dict( 0 , 0 , 0 , 0.69 , 0.92 , 1 ),
ellipse_dict( 0 , -0.0184, 0 , 0.6624, 0.874, -0.8),
ellipse_dict( 0.22, 0 , -18 * np.pi / 360, 0.11 , 0.31 , -0.2),
ellipse_dict(-0.22, 0 , 18 * np.pi / 360, 0.16 , 0.41 , -0.2),
ellipse_dict( 0 , 0.35 , 0 , 0.21 , 0.25 , 0.1),
ellipse_dict( 0 , 0.1 , 0 , 0.046 , 0.046, 0.1),
ellipse_dict( 0 , -0.1 , 0 , 0.046 , 0.046, 0.1),
ellipse_dict(-0.08, -0.605 , 0 , 0.046 , 0.023, 0.1),
ellipse_dict( 0 , -0.605 , 0 , 0.023 , 0.023, 0.1),
ellipse_dict( 0.06, -0.605 , 0 , 0.023 , 0.046, 0.1)
]
def shepp_logan_image(n):
img = np.zeros((n, n), dtype=float)
pixel_centers = np.linspace(-1 + 1/n, 1 - 1/n, n)
grid_x, grid_y = np.meshgrid(pixel_centers, -pixel_centers)
for e in shepp_logan_data:
S_inv = np.array([ # inverse Skalierungsmatrix
[1 / e['axis1'], 0 ],
[0, 1 / e['axis2']]
])
R_inv = np.array([ # inverse Rotationsmatrix
[ np.cos(e['angle']), np.sin(e['angle'])],
[-np.sin(e['angle']), np.cos(e['angle'])]
])
A = S_inv @ R_inv
x = grid_x - e['x']
y = grid_y - e['y']
f = (A[0, 0] * x + A[0, 1] * y) ** 2 + (A[1, 0] * x + A[1, 1] * y) ** 2
img[f < 1] += e['value']
return img
fig, ax = plt.subplots()
ax.imshow(
shepp_logan_image(300),
cmap='gray',
interpolation='none',
extent=(-1, 1, -1, 1)
)
ax.set_xticks([-1, 0, 1])
ax.set_yticks([-1, 0, 1])
plt.show()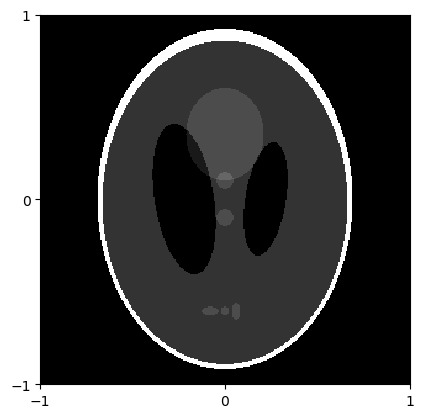
Wesentlicher Grund für die breite Verwendung des Shepp-Logan-Phantoms ist, dass man das Sinogramm in beliebiger Auflösung exakt berechnen kann. Auch für einige andere einfache geometrische Objekte neben Ellipsen ist die Radon-Transformation analytisch auswertbar. Die sich ergebenden Formeln findet man in The Radon Transform - Theory and Implementation (Toft, 1996) ab Seite 199.
def shepp_logan_sinogram(angles, n_pixels):
n_angles = len(angles)
sino = np.zeros((n_pixels, n_angles), dtype=float)
alpha, sigma = np.meshgrid(
angles + 0.5 * np.pi, # Winkel \theta in Toft 1996 (Seite 24)
np.linspace(1 - 1/n_pixels, -1 + 1/n_pixels, n_pixels)
)
for e in shepp_logan_data:
# Berechnungen aus Toft 1996 (Seite 200) entnommen
tmp0 = e['axis1'] ** 2 * np.cos(alpha - e['angle']) ** 2 \
+ e['axis2'] ** 2 * np.sin(alpha - e['angle']) ** 2
tmp = (sigma - e['x'] * np.cos(alpha) - e['y'] * np.sin(alpha)) ** 2
sino += 2 * e['value'] * e['axis1'] * e['axis2'] \
* 1/tmp0 * np.sqrt(np.maximum(0, tmp0 - tmp))
return sino
fig, ax = plt.subplots()
ax.imshow(
shepp_logan_sinogram(np.linspace(0, 2 * np.pi, 300, endpoint=False), 360),
cmap='gray',
interpolation='none',
extent=(0, 2 * np.pi, -1, 1),
aspect='auto'
)
ax.set_xlabel('Winkel')
ax.set_xticks([0, np.pi, 2 * np.pi])
ax.set_xticklabels(['0', '$\\pi$', '$2\\pi$'])
ax.set_yticks([-1, 0, 1])
plt.show()
Aufgrund der Symmetrie kann das Objekt bereits aus den Daten für den Winkelbereich rekonstruiert werden. Genauer gilt:
Vorerst arbeiten wir mit (bis auf Rundungsfehler) exakten Daten. Später, wenn das prinzipielle Vorgehen zur Rekonstruktion geklärt ist, werden wir die Testdaten realitätsnäher gestalten.
5.4Lösungsansätze¶
Betrachten hier kurz drei grundlegend verschiedene Lösungsansätze. Für die ersten beiden belassen wir es bei einem Proof-of-Concept. Den dritten werden wir im Anschluss detaillierter betrachten.
Die ersten beiden im Folgenden vorgestellten Lösungsansätze diskretisieren spät. Der dritte Ansatz diskretisiert hingegen das Modell direkt und löst dann das diskrete Problem.
5.4.1Direktes Fourier-Verfahren¶
Die Radon-Transformation ist eng mit der kontinuierlichen Fourier-Transformation verbunden.
Der Zentralschnitt-Satz besagt, dass man aus den Fourier-Transformationen der einzelnen Projektionen die (zweidimensionale) Fourier-Transformation des Objekts erhält (IDVID 525).
Für das Invertieren der Radon-Transformation ergibt sich daraus folgender Ablauf:
Fourier-Transformation für jede Projektion berechnen.
Fourier-Transformierte des Objekts aus den transformierten Projektionen zusammensetzen.
Inverse (zweidimensionale) Fourier-Transformation anwenden.
Theoretisch erhält man so recht einfach die Lösung. Praktisch gibt es aber zwei wesentliche Probleme:
Software-Bibliotheken für das numerische Rechnen (z.B. NumPy, SciPy) bieten meist nur Implementierungen der Fourier-Transformation für periodische Funktionen, welche mittels schneller Fourier-Transformation sehr effizient berechnet werden kann. Die numerische Berechnung der kontinuierlichen Fourier-Transformation ist mit Blick auf Implementierungs- und Rechenaufwand deutlich anspruchsvoller.
Die diskretisierte Version von Schritt 2 im obigen Ablauf liefert die Fourier-Transformierte des Objekts auf einem polaren Gitter. Für die inverse Fourier-Transformation in Schritt 3 werden aber Daten auf einem Rechteckgitter benötigt (IDVID 530). Also muss interpoliert werden, was zu verhältnismäßig großen Fehlern im Ergebnis führt. Ein möglicher Ausweg ist das Verwenden der noch recht neuen Schnellen Fourier-Transformation auf nichtäquidistanten Stützstellen.
Die folgende Implementierung dient nur als “Proof-of-Concept”. Sie löst die beiden genannten Probleme sehr unsauber durch Verwenden stückweise linearer Interpolation und der schnellen Fourier-Transformation auf etwas umstrukturierten Daten. Für Produktiv-Code sollte glattere Interpolation und eine saubere Diskretisierung der kontinuierlichen Fourier-Transformation implementiert werden, was allerdings unsere mathematischen Fähigkeiten übersteigt.
import scipy.interpolate
n_angles = 180
n_sino_pixels = 300
n_img_pixels = 300 # muss gleich n_sino_pixels sein, sonst Rekonstruktion
# gezoomt (wegen schlechter Implementierung der F-Trafos)
# Sinogramm
angles = np.linspace(0, np.pi, n_angles, endpoint=False)
sino = shepp_logan_sinogram(angles, n_sino_pixels)
# Fourier-Transformation der einzelnen Projektionen
sino_fourier = np.fft.fftshift(
np.fft.fft(
np.fft.ifftshift(
sino - sino.mean(axis=0),
axes=(0,)
),
axis=0
),
axes=(0,)
)
# polares Gitter (an diesen Stellen kennen wir die 2D-F-Transformierte)
polar_grid_phi, polar_grid_r = np.meshgrid(
angles + 0.5 * np.pi, # Winkel der Projektions"fläche" bzgl. x-Achse
np.linspace(1 - 1/n_sino_pixels, -1 + 1/n_sino_pixels, n_sino_pixels)
)
# Rechteckgitter (an diesen Stellen benötigen wir die 2D-F-Transformierte)
rect_grid_x, rect_grid_y = np.meshgrid(
np.linspace(-1 + 1/n_img_pixels, 1 - 1/n_img_pixels, n_img_pixels),
np.linspace(1 - 1/n_img_pixels, -1 + 1/n_img_pixels, n_img_pixels)
)
# Interpolation
interpolator = scipy.interpolate.LinearNDInterpolator(
np.hstack((
(polar_grid_r * np.cos(polar_grid_phi)).reshape(-1, 1),
(polar_grid_r * np.sin(polar_grid_phi)).reshape(-1, 1)
)),
sino_fourier.reshape(-1),
fill_value=0
)
sin_fourier_rect = interpolator(rect_grid_x, rect_grid_y)
# inverse 2D-Fourier-Transformation
img = np.fft.fftshift(
np.fft.ifft2(
np.fft.ifftshift(
sin_fourier_rect
)
)
).real # sollte theoretisch reell sein, ist es aber aufgrund von
# Fehlern (Diskretisierung,...) nicht
# exakte Lösung zum Vergleich
img_exact = shepp_logan_image(n_img_pixels)
fig, ax = plt.subplots()
ax.imshow(sino, cmap='gray', extent=(0, np.pi, -1, 1))
ax.set_title('Sinogramm')
ax.set_xticks([0, 0.5 * np.pi, np.pi])
ax.set_xticklabels(['0', '$\\pi/2$', '$\\pi$'])
ax.set_yticks([-1, 0, 1])
plt.show()
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 4))
ax1.imshow(img_exact, cmap='gray', extent=(-1, 1, -1, 1))
ax1.set_title('exakte Lösung')
ax1.set_xticks([-1, 0, 1])
ax1.set_yticks([-1, 0, 1])
ax2.imshow(img, cmap='gray', extent=(-1, 1, -1, 1))
ax2.set_title('Rekonstruktion')
ax2.set_xticks([-1, 0, 1])
ax2.set_yticks([-1, 0, 1])
plt.show()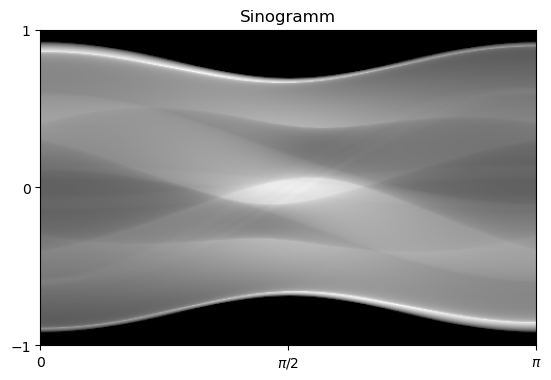
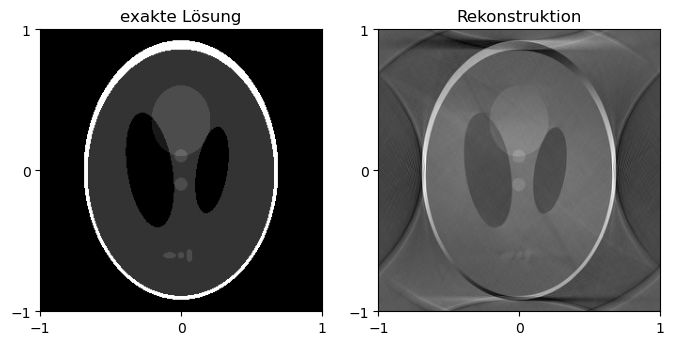
Die in der Rekonstruktion zusätzlich vorhandenen Strukturen werden als Artefakte bezeichnet. Sie entstehen aufgrund der Diskretisierung und sind auch bei besserer Implementierung der Fourier-Transformationen nicht ganz vermeidbar. Aufgrund der recht starken Artefakte beim direkten Fourier-Verfahren hat dieses in der Praxis kaum Relevanz.
5.4.2Gefilterte Rückprojektion¶
Die gefilterte Rückprojektion verfolgt die gleiche Idee wie das direkte Fourier-Verfahren (Zentralschnitt-Satz), verzichtet aber auf das numerische Invertieren der zweidimensionalen Fourier-Transformation. Stattdessen wird ein Teil der Berechnung analytisch ausgeführt, sodass das Gitterproblem (polar vs. rechteckig) vermieden wird. Als Ergebnis erhält man den folgenden Ablauf:
Fourier-Transformation für jede Projektion berechnen.
Jede Fourier-transformierte Projektion mit der Funktion multiplizieren (“ramp filter”).
Inverser Fourier-Transformation auf jede gefilterte und transformierte Projektion anwenden.
Gefilterte Projektionen invertieren (liefert “Streifenbilder”).
Streifenbilder aller Projektionen überlagern/addieren.
Dieses Vorgehen liefert (theoretisch) die exakte Lösung.
“Proof-of-Concept” mit unsauber diskretisierter Fourier-Transformation:
n_angles = 180
n_sino_pixels = 300
n_img_pixels = 300
# Sinogramm
angles = np.linspace(0, np.pi, n_angles, endpoint=False)
sino = shepp_logan_sinogram(angles, n_sino_pixels)
# Fourier-Transformation der einzelnen Projektionen
sino_fourier = np.fft.fftshift(
np.fft.fft(
np.fft.ifftshift(
sino,
axes=(0,)
),
axis=0
),
axes=(0,)
)
# Filtern der transformierten Projektionen
sino_pixel_centers = np.linspace(
-1 + 1/n_sino_pixels, 1 - 1/n_sino_pixels, n_sino_pixels
)
ramp_filter = np.abs(sino_pixel_centers)
sino_fourier_filtered = ramp_filter.reshape(-1, 1) * sino_fourier
# inverse Fourier-Transformation der einzelnen Projektionen
sino_filtered = np.fft.ifftshift(
np.fft.ifft(
np.fft.fftshift(
sino_fourier_filtered,
axes=(0,)
),
axis=0
),
axes=(0,)
).real # sollte theoretisch reell sein, ist es aber aufgrund von
# Fehlern (Diskretisierung,...) nicht
# Rückprojektion
grid_x, grid_y = np.meshgrid(
np.linspace(-1 + 1/n_img_pixels, 1 - 1/n_img_pixels, n_img_pixels),
np.linspace(1 - 1/n_img_pixels, -1 + 1/n_img_pixels, n_img_pixels)
)
img = np.zeros((n_img_pixels, n_img_pixels), dtype=float)
for i, angle in enumerate(angles):
sigma = np.cos(angle + 0.5 * np.pi) * grid_x \
+ np.sin(angle + 0.5 * np.pi) * grid_y
img += np.interp( # Sinogrammspalte an beliebigen Stellen auswerten
sigma,
sino_pixel_centers, sino_filtered[::-1, i],
left=0, right=0
)
# exakte Lösung zum Vergleich
img_exact = shepp_logan_image(n_img_pixels)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 4))
ax1.imshow(sino, cmap='gray', extent=(0, np.pi, -1, 1))
ax1.set_title('Sinogramm')
ax1.set_xticks([0, 0.5 * np.pi, np.pi])
ax1.set_xticklabels(['0', '$\\pi/2$', '$\\pi$'])
ax1.set_yticks([-1, 0, 1])
ax2.imshow(sino_filtered, cmap='gray', extent=(0, np.pi, -1, 1))
ax2.set_title('Sinogramm (gefiltert)')
ax2.set_xticks([0, 0.5 * np.pi, np.pi])
ax2.set_xticklabels(['0', '$\\pi/2$', '$\\pi$'])
ax2.set_yticks([-1, 0, 1])
plt.show()
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8, 4))
ax1.imshow(img_exact, cmap='gray', extent=(-1, 1, -1, 1))
ax1.set_title('exakte Lösung')
ax1.set_xticks([-1, 0, 1])
ax1.set_yticks([-1, 0, 1])
ax2.imshow(img, cmap='gray', extent=(-1, 1, -1, 1))
ax2.set_title('Rekonstruktion')
ax2.set_xticks([-1, 0, 1])
ax2.set_yticks([-1, 0, 1])
plt.show()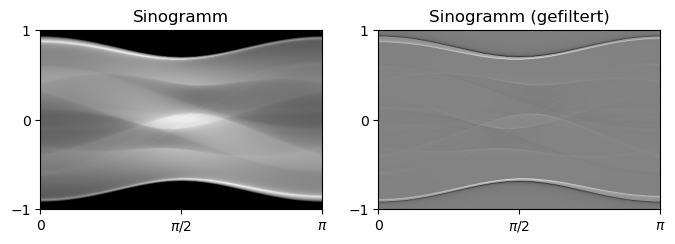

Der Unterschied zwischen gefilterter Rückprojektion und dem direkten Fourier-Verfahren besteht nur in der Frage, ab ein Teil der Integrale in der Formel für die inverse zweidimensionale Fourier-Transformation analytisch oder numerisch berechnet wird! Für das auftretende Doppelintegral wird eine Koordinatentransformation durchgeführt und anschließend das dann innere Integral analytisch berechnet.
5.4.3Diskretisieren der Radon-Transformation¶
Ein einfacher Lösungsansatz, der komplexere mathematische Werkzeuge vermeidet und auch bei zahlreichen anderen Aufgaben des wissenschaftlichen Rechnens anwendbar ist, ist das direkte Diskretisieren des “Vorwärtsoperators”, hier also der Radon-Transformation. Die Radon-Transformation ist eine lineare Abbildung. Also sollte man erwarten können, dass nach geeigneter Diskretisierung aller beteiligten Größen ein lineares Gleichungssystem entsteht. Dieses kann dann mit Standardverfahren gelöst werden.
Diesen Ansatz werden wir in Kürze detailliert umsetzen. Hier zunächst nur der grobe Ablauf:
Wähle eine Basis im Lösungsraum, also eine (endliche) Menge von Funktionen , , sodass jede Lösung näherungsweise als Linearkombination
dargestellt werden kann.
Stelle die Matrix auf, die den Vektor auf die gegebenen diskreten Sinogrammdaten abbildet. Dabei ist der Vektor, der untereinander alle Spalten des Sinogramms enthält.
Löse das lineare Gleichungssystem
und berechne die zum Lösungsvektor gehörende Linearkombination der Basisfunktionen.
Drei Schwierigkeiten sind zu überwinden:
Wie Basis wählen? Das ist eine Abwägung zwischen Einfachheit und “algorithmischer Raffinesse”. Die einfachste Wahl ist die sogenannte Pixelbasis. Jedes repräsentiert genau ein Pixel, hat also den Wert 1 für alle , die in der Pixelfläche liegen und sonst den Wert Null. Alternativ könnte man z.B. eine Wavelet-Basis wählen, die zusätzliche Möglichkeiten bei der Unterdrückung von (unter Umständen) extremer Fehlerverstärkung im Lösungsprozess bietet (siehe unten) und insbesondere bei hohen Bildauflösungen eine speichereffizientere Darstellung der Bilddaten erlaubt.
Wie Matrix aufstellen? Dies ist eine reine Rechenübung! Wählt man im ersten Schritt die Pixelbasis, so entspricht jede Spalte der Matrix gerade dem Sinogramm des entsprechenden Pixels (IDVID 540). Müssen also die Radon-Transformierte für jedes einzelne Pixel berechnen.
Passt die Matrix in den Speicher? Schon bei moderater Auflösung von 200 mal 200 Pixel für die Lösung, 200 Pixel pro Sinogrammspalte und 120 Projektionswinkeln hat die Matrix fast eine Milliarde Einträge (genau: 960000000). Bei Verwendung von 64-Bit-Gleitkommazahlen entspricht dies 8 GB Arbeitsspeicherbedarf! Wird die Auflösung verdoppelt, sind es schon 32 GB. ABER: Die meisten Einträge von sind Null, da die Spalten gerade die Sinogramme einzelner Pixel sind. Verwendet man spezielle Speicherformate für dünn besetzte Matrizen, so kann die Matrix problemlos im Speicher abgelegt werden (vgl. auch Veranstaltung zur numerischen Mathematik).
5.5Umsetzung der direkten Diskretisierung¶
Setzen den dritten Lösungsansatz nun um.
5.5.1Radon-Matrix¶
Die Matrixdarstellung der Radon-Transformation entsteht spaltenweise aus den Sinogrammen einzelner Pixel (vgl. oben).
5.5.1.1Relevante Pixel¶
Der Aufnahmebereich von Computertomografen ist üblicherweise rund, z.B. die Kreisfläche mit Radius 1 um den Ursprung. Bilddaten im Computer werden hingegen zweckmäßig als rechteckige Anordnung von quadratischen Pixeln dargestellt, z.B. für das um Ursprung zentrierte, achsenparallele Quadrat mit Kantenlänge 2. Entsprechend bleiben einige Pixel außerhalb der Kreisscheibe ungenutzt.
Bei der Implementierung sollten die ungenutzen Pixel keine Auswirkung auf das Sinogramm haben, also die entsprechenden Spalten in der Matrix auf Null gesetzt werden. Nur die Pixel, die vollständig von der Kreisscheibe mit Radius 1 überdeckt werden, spielen eine Rolle. Ist der Mittelpunkt eines Pixels mit Kantenlänge , so muss also gelten:
5.5.1.2Radon-Transformation eines Pixels¶
Hat man das Sinogramm eines am Koordinatenursprung zentrierten Pixels zur Hand (siehe unten), so kann man die Sinogramme aller anderen Pixel leicht daraus berechnen, denn für das aus einem Objekt durch Verschiebung entstandene Objekt gilt:
(IDVID 545).
Die Radon-Transformation eines im Koordinatenursprung zentrierten Pixels lässt sich leicht berechnen. Im einfachsten Fall kann man das Pixel als Kreisscheibe betrachten. Dann ist die Radon-Transformierte für alle Projektionswinkel gleich. Die heute übliche Darstellung von Pixeln als Quadrat erfordert etwas mehr Rechenaufwand, ist aber noch gut machbar. Für ein am Koordinatenursprung zentriertes quadratisches Pixel genügt die Betrachtung des Winkelbereichs und der positiven Hälfte der Detektorpositionen, also . Alle anderen Sinogrammwerte ergeben sich aus Symmetrieeigenschaften des Quadrats (IDVID 550):
Symmetrie des Quadrats an der -Achse:
Rotationssymmetrie des des Quadrats bzgl. Drehungen um Vielfache von :
Symmetrie von Sinogrammen:
Anwenden der beider vorherigen Eigenschaften liefert:
Für verschobene Objekte erhält man daraus:
(IDVID 553).
Beträgt die Kantenlänge des Pixels , so erhält man für und
sowie für
(IDVID 555).
5.5.1.3Diskretisierung der Projektionswinkel¶
Die Diskretisierung der Projektionswinkel folgt den praktischen Gegebenheiten: Die Aufnahmen werden für eine endliche Anzahl von Winkeln durchgeführt. Üblicherweise sind diese gleichmäßig über das Intervall verteilt.
Möchte man den Fall vermeiden, kann man die Winkel wie folgt wählen:
5.5.1.4Diskretisierung der Sinogrammspalten¶
Für gegebenen festen Winkel müssen wir die Funktion
durch endlich viele Werte darstellen. Hier ist der Bezug zum Messvorgang nicht mehr so klar wie bei den Winkeln. Besitzt der Computertomograf gleichmäßig verteilte Detektoren und gehen wir (sehr idealisiert) von linienförmigem Strahlverlauf direkt durch die Mitten der Detektoren aus, so entstehen die Detektormesswerte als Funktionsauswertungen
mit
(IDVID 558).
5.5.1.5Nicht-Null-Einträge¶
Die meisten Einträge der Matrix sind Null und sollen aus Platzgründen nicht im Arbeitsspeicher liegen. Müssen also für jedes Bildpixel und für jeden Winkel die Indizes bestimmen, für die gilt. Nur diese werden im Arbeitsspeicher abgelegt (vgl. nächsten Abschnitt).
Für erhalten wir
wobei
und
Für erhalten wir
wobei
(IDVID 560).
5.5.1.6Implementierung¶
Dünn besetzte Matrizen werden von NumPy nicht unterstützt, aber von SciPy. Es gibt verschiedene Typen, die sich in Implementierungsdetails unterscheiden und für manche Zwecke besser als für andere geeignet sind. Wir wollen im Wesenlichen Matrix-Vektor-Produkte berechnen, was mit dem Typ csr_array effizient möglich ist. Die Nicht-Null-Einträge der Matrix sind dem Konstruktor als Listen der Einträge, der Zeilenindizes und der Spaltenindizes zu übergeben.
Der folgende Code kann mit Blick auf die Rechenzeit noch optimiert werden, verzichet zum Zwecke der leichteren Übertragbarkeit in andere Sprachen aber auf übermäßige Verwendung von Python- und NumPy-Features wie Broadcasting und boolsches Indizieren.
import scipy.sparse as ss
def radon_matrix(n_img_pixels, n_sino_pixels, n_angles):
# Pixelanzahlen günstig wählen für einfachere Implementierung
if n_img_pixels % 2 != 0:
print('Bildbreite bzw. -höhe muss durch 2 teilbar sein!')
return None
if n_angles % 8 != 0:
print('Winkelanzahl muss durch 8 teilbar sein!')
return None
if n_sino_pixels % 2 != 0:
print('Pixelanzahl in den Sinogrammspalten muss durch 2 teilbar sein!')
return None
# Listen für Nicht-Null-Einträge der Matrix A
Adata = []
Acols = []
Arows = []
# Funktion zum Schreiben einer Sinogrammspalte in die Matrix A
def set_sino_col(kmin, kmax, s_nonzero, flip_s,
sino_col, col, flip_col, row, flip_row):
# Vorzeichen vor x-Koordinate des Bildpixels drehen?
if flip_col:
col = n_img_pixels - 1 - col
# Vorzeichen vor y-Koordinate des Bildpixels drehen?
if flip_row:
row = n_img_pixels - 1 - row
# Sinogrammspalte am Ursprung spiegeln?
if flip_s:
kmin, kmax = n_sino_pixels - 1 - kmax, n_sino_pixels - kmin - 1
s_nonzero = s_nonzero[::-1]
# Position der Sinogrammspalte in A berechnen
Acol = col * n_img_pixels + row
Arow = sino_col * n_sino_pixels
# Daten in A schreiben
Adata.extend(list(s_nonzero))
Acols.extend((kmax - kmin + 1) * [Acol])
Arows.extend(list(range(Arow + kmin, Arow + kmax + 1)))
# Sinogramme erstellen
# (Pixel (x, y) und (-x, -y) haben gerade gespiegelte Sinogrammspalten,
# sodass nur die Hälfte der Pixel durchlaufen werden muss)
a = 1 / n_img_pixels # halbe Pixelbreite
n_angles4 = n_angles // 4 # entspricht Winkel pi/2
all_x0 = np.linspace(-1 + a, 1 - a, n_img_pixels)
all_y0 = np.linspace(1 - a, 0 + a, n_img_pixels // 2)
angles = np.linspace(
np.pi / n_angles, 0.25 * np.pi - np.pi / n_angles, n_angles // 8
)
s = np.empty(n_sino_pixels, dtype=float) # temporäre Sinogrammspalte
for (img_col, x0) in enumerate(all_x0):
for (img_row, y0) in enumerate(all_y0):
# nur Pixel innerhalb der Kreisscheibe!
if (np.abs(x0) + a) ** 2 + (np.abs(y0) + a) ** 2 > 1:
continue
# Winkel zwisch 0 und pi/4 (Rest mittels Spiegeln und Verschieben)
for (i_alpha, alpha) in enumerate(angles):
cos = np.cos(alpha)
sin = np.sin(alpha)
# Index-Range der Nicht-Null-Einträge (zunächst ungültige Werte)
kmin, kmax = n_sino_pixels, -1
# Index-Ranges der verschiedenen Abschnitte der Sinogrammspalte
c = 1 - 1 / n_sino_pixels # zur Vereinfachung der 4 Formeln
kuu = int(np.floor(
n_sino_pixels / 2 * (c + (x0 - a) * sin - (y0 + a) * cos) + 1
))
ku = int(np.ceil(
n_sino_pixels / 2 * (c + (x0 + a) * sin - (y0 + a) * cos)
))
ko = int(np.floor(
n_sino_pixels / 2 * (c + (x0 - a) * sin - (y0 - a) * cos)
))
koo = int(np.ceil(
n_sino_pixels / 2 * (c + (x0 + a) * sin - (y0 - a) * cos) - 1
))
# Sinogrammwerte für jeden Abschnitt setzen
if kuu < ku:
c = 1 - (1 + 2 * np.arange(kuu, ku)) / n_sino_pixels
s[kuu:ku] = (-(x0 - a) * sin + (y0 + a) * cos - c) / (cos * sin)
kmin, kmax = kuu, ku - 1
if ku <= ko:
s[ku:(ko + 1)] = 2 * a / cos
kmin, kmax = np.minimum(kmin, ku), np.maximum(kmax, ko)
if ko < koo:
c = 1 - (1 + 2 * np.arange(ko + 1, koo + 1)) / n_sino_pixels
s[(ko + 1):(koo + 1)] \
= ((x0 + a) * sin - (y0 - a) * cos + c) / (cos * sin)
kmin, kmax = np.minimum(kmin, ko + 1), np.maximum(kmax, koo)
s_nonzero = s[kmin:(kmax + 1)]
# 0...0.25pi
set_sino_col(
kmin, kmax, s_nonzero, False, i_alpha,
img_col, False, img_row, False
)
set_sino_col(
kmin, kmax, s_nonzero, True, i_alpha,
img_col, True, img_row, True
)
# 0.25pi...0.5pi
set_sino_col(
kmin, kmax, s_nonzero, False, n_angles4 - 1 - i_alpha,
img_row, False, img_col, False
)
set_sino_col(
kmin, kmax, s_nonzero, True, n_angles4 - 1 - i_alpha,
img_row, True, img_col, True
)
# 0.5pi...0.75pi
set_sino_col(
kmin, kmax, s_nonzero, False, n_angles4 + i_alpha,
img_row, False, img_col, True
)
set_sino_col(
kmin, kmax, s_nonzero, True, n_angles4 + i_alpha,
img_row, True, img_col, False
)
# 0.75pi...pi
set_sino_col(
kmin, kmax, s_nonzero, False, 2 * n_angles4 - 1 - i_alpha,
img_col, False, img_row, True
)
set_sino_col(
kmin, kmax, s_nonzero, True, 2 * n_angles4 - 1 - i_alpha,
img_col, True, img_row, False
)
# pi...1.25pi
set_sino_col(
kmin, kmax, s_nonzero, False, 2 * n_angles4 + i_alpha,
img_col, True, img_row, True
)
set_sino_col(
kmin, kmax, s_nonzero, True, 2 * n_angles4 + i_alpha,
img_col, False, img_row, False
)
# 1.25pi...1.5pi
set_sino_col(
kmin, kmax, s_nonzero, False, 3 * n_angles4 - 1 - i_alpha,
img_row, True, img_col, True
)
set_sino_col(
kmin, kmax, s_nonzero, True, 3 * n_angles4 - 1 - i_alpha,
img_row, False, img_col, False
)
# 1.5pi...1.75pi
set_sino_col(
kmin, kmax, s_nonzero, False, 3 * n_angles4 + i_alpha,
img_row, True, img_col, False
)
set_sino_col(
kmin, kmax, s_nonzero, True, 3 * n_angles4 + i_alpha,
img_row, False, img_col, True
)
# 1.75pi...2pi
set_sino_col(
kmin, kmax, s_nonzero, False, n_angles - 1 - i_alpha,
img_col, True, img_row, False
)
set_sino_col(
kmin, kmax, s_nonzero, True, n_angles - 1 - i_alpha,
img_col, False, img_row, True
)
# Matrix aus Listen erstellen
A = ss.csr_array(
(Adata, (Arows, Acols)),
shape=(n_sino_pixels * n_angles, n_img_pixels ** 2)
)
return A
# Matrix erstellen
n_sino_pixels = 100
n_angles = 200
n_img_pixels = int(np.ceil(np.sqrt(2 * n_sino_pixels * n_angles / np.pi) / 2) * 2)
print(f'Bildpixel: {n_img_pixels} x {n_img_pixels}')
A = radon_matrix(n_img_pixels, n_sino_pixels, n_angles)
# Anzahl Nicht-Null-Einträge
size = A.shape[0] * A.shape[1]
nonzeros = len(A.nonzero()[0])
print(f'Einträge in A gesamt: {size:10}')
print(f'Nicht-Null-Einträge: {nonzeros:10}')
print(f'Besetzungsdichte: {nonzeros / size * 100:9.2f}%')Bildpixel: 114 x 114
Einträge in A gesamt: 259920000
Nicht-Null-Einträge: 2225296
Besetzungsdichte: 0.86%
Zum Test wenden wir die Matrix auf das diskretisierte Shepp-Logan-Phantom an.
img_exact = shepp_logan_image(n_img_pixels)
angles = np.linspace(np.pi / n_angles, 2 * np.pi - np.pi / n_angles, n_angles)
exact_sino = shepp_logan_sinogram(angles, n_sino_pixels)
u_exact = img_exact.T.reshape(-1)
v = A @ u_exact
sino = v.reshape(n_angles, n_sino_pixels).T
fig, ax = plt.subplots()
ax.imshow(img_exact, cmap='gray')
plt.show()
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5))
ax1.imshow(sino, cmap='gray')
ax2.imshow(exact_sino, cmap='gray')
ax1.set_title('mit $A$ berechnetes Sinogramm')
ax2.set_title('diskretisiertes exaktes Sinogramm')
plt.show()
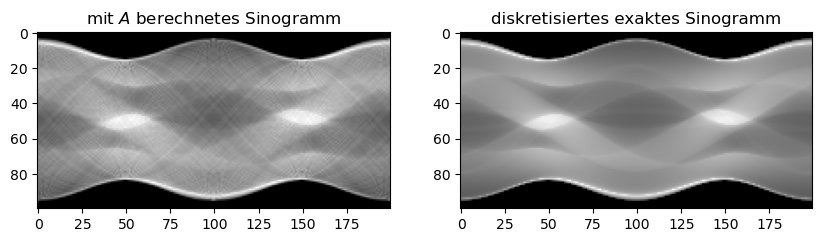
Die Abweichungen zwischen den beiden Sinogrammen entstehen durch die unterschiedlichen Ansätze:
links: erst diskretisieren, dann Sinogramm berechnen,
rechts: erst Sinogramm berechnen, dann diskretisieren.
5.5.2Lösen des Gleichungssystems¶
Die Matrix ist im Allgemeinen nicht quadratisch, also nicht invertierbar. Wir können das Gleichungssystem also nicht direkt lösen. Einziger Ausweg ist die Suche nach einem Vektor , sodass möglichst nah am gegebenen Datenvektor liegt. Zu lösen ist also das Minimierungsproblem
Dabei ist
die übliche euklidische Norm eines Vektors . Dieser Ansatz ist eng verwandt mit der Methode der kleinsten Quadrate (vgl. Veranstaltung zur Numerik). Insbesondere gibt es stets eine eindeutige Lösung und diese kann aus dem linearen Gleichungssystem
bestimmt werden, welches eine invertierbare quadratische Systemmatrix besitzt, also eindeutig lösbar ist.
Zum Lösen des Gleichungssystems sollte ein Algorithmus verwendet werden, der speziell für dünn besetzte Matrizen entwickelt wurde (vgl. Veranstaltung zur Numerik). Geeignet ist z.B. scipy.sparse.linalg.lsqr.
u = scipy.sparse.linalg.lsqr(A, v, iter_lim=1000)[0]
img = u.reshape(n_img_pixels, n_img_pixels).T
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5))
ax1.imshow(img, cmap='gray')
ax2.imshow(img_exact, cmap='gray')
ax1.set_title('berechnete Lösung')
ax2.set_title('exakte Lösung')
plt.show()
5.5.3Realitätsnahe Daten¶
Um die Arbeit mit synthetischen Testdaten realitätsnäher zu gestalten, sollten zwei wichtige Regeln beachtet werden:
Zum Erzeugen der Daten nicht das diskretisierte Modell (hier die Matrix ) verwenden, sondern die Daten auf vom diskretisierten Lösungsprozess unabhängigem Weg erzeugen. Falls es keinen anderen Weg gibt, dann muss wenigstens eine viel feinere Diskretisierung für die Datenerzeugung verwendet werden. Die eigentlichen Daten entstehen dann durch (vom Lösungsprozess unabhängiges) Down-Sampling.
Die erzeugten Daten sollten mit Rauschen überlagert werden, da dieses bei Realdaten immer auftritt. Nur so können die Auswirkung von eventuellen Instabilitäten des gewählten Lösungsverfahrens (extreme Verstärkung von Datenfehlern) auch an synthetischen Daten beobachtet werden.
Für das Shepp-Logan-Phantom können wir die Daten unabhängig von erzeugen. Um verrauschte Daten mit einem relativen Datenfehler zu erhalten, muss ein zufälliger Vektor erzeugt werden. Setzt man damit
so gilt
# Daten nicht mit A erzeugen!
v = shepp_logan_sinogram(angles, n_sino_pixels).T.reshape(-1)
# 1 Prozent normalverteiltes Rauschen
noise_level = 0.01 # relatives Rauschniveau
rng = np.random.default_rng(0) # Zufallszahlengenerator
noise = rng.normal(size=v.shape)
v_noisy = v + noise_level * np.linalg.norm(v) / np.linalg.norm(noise) * noise
u_noisy = scipy.sparse.linalg.lsqr(A, v_noisy, iter_lim=1000)[0]
img_noisy = u_noisy.reshape(n_img_pixels, n_img_pixels).T
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(10, 10))
vmin = np.minimum(v_noisy.min(), v.min())
vmax = np.maximum(v_noisy.max(), v.max())
ax1.imshow(v_noisy.reshape(n_angles, n_sino_pixels).T, cmap='gray', vmin=vmin, vmax=vmax)
ax2.imshow(v.reshape(n_angles, n_sino_pixels).T, cmap='gray', vmin=vmin, vmax=vmax)
ax1.set_title('verrauschte Daten')
ax2.set_title('Daten ohne Rauschen')
ax3.imshow(img_noisy, cmap='gray')
ax4.imshow(img_exact, cmap='gray')
ax3.set_title('berechnete Lösung')
ax4.set_title('exakte Lösung')
plt.show()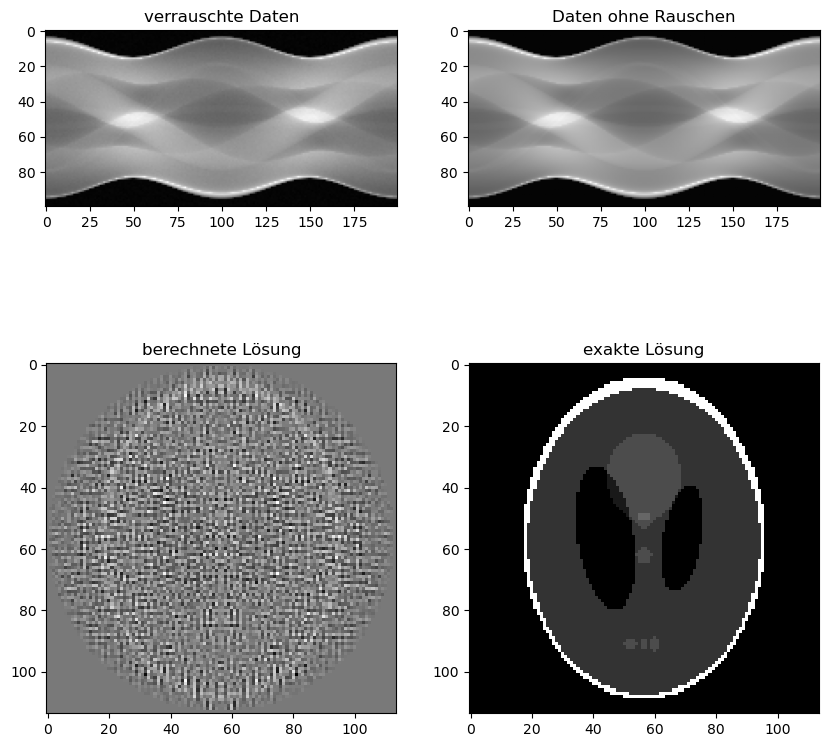
Das Invertieren der Radon-Transformation reagiert extrem empfindlich auf Änderungen in den Daten! Selbst sehr kleine Änderungen können schon zu extremen Abweichungen in der Lösung führen. Die dritte Hadamard-Bedingung ist also nicht erfüllt.
5.5.4Regularisierung¶
Um trotz der beobachteten Instabilität akzeptable Lösungen aus verrauschten Daten zu bekommen kann man so genannte Regularisierungsverfahren einsetzen. Diese ändern das eigentlich zu lösende Problem leicht ab, sodass es stabil wird, aber die Lösungen trotzdem in der Nähe der Lösungen des Ausgangsproblems liegen.
Ein einfaches Regularisierungsverfahren ist die Tikhonov-Regularisierung. Das ursprüngliche Minimierungsproblem wird durch einen Strafterm ergänzt:
Der Regularisierungsparameter ist dabei geeignet zu wählen. Je kleiner er ist, desto näher liegen die Minimierer an den Lösungen des Ausgangproblems, aber desto instabiler ist der Lösungsprozess. Sehr großes liefert Lösungen, die kaum auf Datenfehler reagieren, aber weit weg von den Lösungen des Ausgangsproblems liegen.
Praktisch versucht man unterschiedliche Werte für und wählt den Wert, der die besten Ergebnisse auf synthetischen Daten liefert. Es existieren auch verschiedene automatische Parameterwahlstrategien, die aber keine Garantie für eine gute Wahl liefern.
Das Minimierungsproblem kann wieder in ein lineares Gleichungssystem übersetzt werden:
wobei die Einheitsmatrix ist.
u_noisy = scipy.sparse.linalg.lsqr(A, v_noisy, damp=0.3, iter_lim=1000)[0]
img_noisy = u_noisy.reshape(n_img_pixels, n_img_pixels).T
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5))
ax1.imshow(img_noisy, cmap='gray')
ax2.imshow(img_exact, cmap='gray')
ax1.set_title('berechnete Lösung')
ax2.set_title('exakte Lösung')
plt.show()
Tikhonov-Regularisierung führt meist zu geglätteten Lösungen. Möchte man dies vermeiden, sollte statt der Pixelbasis eine Wavelet-Basis gewählt und der Strafterm durch ersetzt werden. Dann kann der Minimierer allerdings nicht mehr als Lösung eines lineare Gleichungssystems berechnet werden. Stattdessen kommen speziell für diese Situation entwickelte Algorithmen zum Einsatz.
Ein andere Regularisierungstechnik ist die Verwendung einer sehr niedrigen Auflösung, was in der Praxis aber nur selten akzeptabel ist.
n_img_pixels = 50
A = radon_matrix(n_img_pixels, n_sino_pixels, n_angles)
u_noisy = scipy.sparse.linalg.lsqr(A, v_noisy, iter_lim=1000)[0]
img_noisy = u_noisy.reshape(n_img_pixels, n_img_pixels).T
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5))
ax1.imshow(img_noisy, cmap='gray')
ax2.imshow(img_exact, cmap='gray')
ax1.set_title('berechnete Lösung')
ax2.set_title('exakte Lösung')
plt.show()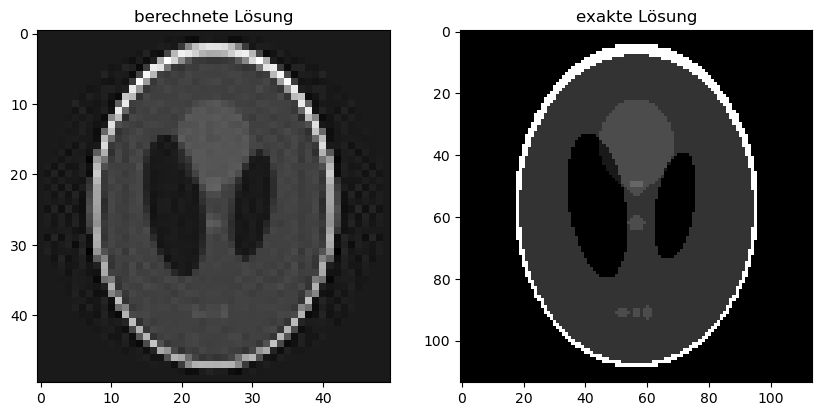
5.5.5Zusammenfassung¶
Einige Erkenntnisse seien nochmal zusammengefasst:
Kontinuierliche Modelle sind zwar praxisfern, erlauben aber die Konzentration auf die physikalischen/technischen Zusammenhänge. Man kann das Problem “sehen” ohne sich in den Details der (endlichdimensionalen) Implementierung zu verlieren.
Es gibt stets eine Vielzahl von Lösungsmöglichkeiten. Im Zweifelsfall gilt: “Keep it simple”. Und: Literaturrecherche ist immer eine gute Idee!
Das Diskretisieren von Modellen ist ein aufwendiger und fehleranfälliger, aber unvermeidbarer Vorgang, der (fast immer) von Hand und sehr gewissenhaft durchgeführt werden muss.
Zunächst mit “sauberen” Daten das prinzipielle Vorgehen testen. Anschließend unbedingt auch mit realitätsnahen Daten testen.
Rechenaufwand kann relevant sein (Lösen des Gleichungssystems) oder völlig egal (Aufstellen der Matrix). Immer den Praxiseinsatz im Blick behalten!
5.6Realdaten¶
Wollen unser Vorgehen mit Realdaten testen. Rohe, also unverarbeitete Sinogrammdaten von kommerziellen CT-Geräten sind kaum öffentlich verfügbar. Allerdings gibt es Datensätze von für akademische Zwecke gebauten Geräten. Ein gute Quelle ist die Finnish Inverse Problems Society, welche zum Beispiel Sinogrammdaten einer Walnuss anbietet.
5.6.1Datensatz¶
Der Walnuss-Datensatz ist in Tomographic X-ray data of a walnut genauer beschrieben. Einige Eckdaten:
selbst gebautes CT-Geräte,
punktförmige Quelle, also keine parallelen Strahlen, sondern fächerförmiger Strahlverlauf,
flacher Detektor (was unüblich ist bei Fächerstrahl-CT-Geräten),
Sinogrammdaten für 120 und 1200 Aufnahmewinkel mit 2296 Sinogrammpixeln,
weitere durch Downsampling gewonnene Sinogramme mit 82, 164, 328 Sinogrammpixeln,
Mit enthalten im Datensatz sind die Radon-Matrizen bzgl. der Pixelbasis. Wir müssen also nicht nochmal selbst die Radon-Transformation diskretisieren.
from scipy.io import loadmat
data_dict = loadmat('walnut_data164.mat')
print('keys:')
for key in data_dict:
print(' ', key)
A = data_dict['A']
print('A:', A.shape, type(A))
sino = data_dict['m']
print('sino:', sino.shape, type(sino))
fig, ax = plt.subplots()
ax.imshow(sino, cmap='gray')
plt.show()keys:
__header__
__version__
__globals__
A
m
A: (19680, 26896) <class 'scipy.sparse._csc.csc_matrix'>
sino: (164, 120) <class 'numpy.ndarray'>

5.6.2Lösungsansätze für gefächerte Strahlen¶
Bisher haben wir nur Computertomografie mit parallel verlaufenden Strahlen betrachtet. Praktisch alle modernen CT-Geräte arbeiten aber mit fächerförmigem oder noch komplexerem (3D) Strahlverlauf. Zur Diskretisierung gefächerter Verläufe gibt es zwei grundlegende Ansätze:
Analog zu unserem Vorgehen bei parallelen Strahlen wird für jedes Pixel (bzw. jede Basisfunktion) und jeden Strahlwinkel die zugehörige Sinogrammspalte berechnet.
Man sortiert die Spalten der Sinogramme zwischen den verschiedenen Aufnahmewinkeln um und erhält so Sinogrammdaten für parallele Strahlen (IDVID 570). So kann die oben für parallele Strahlen berechnete Matrix auch für gefächerte Strahlen verwendet werden. Dieser Ansatz wird als Rebinning bezeichnet. Problematisch ist dabei, dass die so erhaltenen (parallelen) Aufnahmewinkel und Pixelpositionen im Sinogramm nicht mehr äquidistant sind, sodass Qualitätsverluste durch notwendiges Resampling der Daten entstehen können.
5.6.3Rekonstruktion¶
Schwierigster Punkt bei der Rekonstruktion ist die Wahl des Regularisierungsparameters. Für erhalten wir keine sinnvolle Rekonstruktion. Für größere Werte werden die Rekonstruktionen besser. Die Wahl eines guten Parameters hängt von vielen Faktoren ab, insbesondere vom Rauschniveau in den Daten. Über das Rauschniveau liegen uns allerdings keinerlei Informationen vor, sodass wir nur verschiedene Werte für ausprobieren und die zugehörigen Rekonstruktionen durch manuelle Inspektion bewerten können. Im Prinzip könnte man das zu erwartende Rauschniveau aus entsprechenden Angaben zur verwendeten Hardware ermitteln. Dies ist im vorliegenden Fall jedoch nicht geschehen oder nicht mit veröffentlicht worden.
v = sino.T.reshape(-1)
u1 = scipy.sparse.linalg.lsqr(A, v, damp=1, iter_lim=1000)[0]
img1 = u1.reshape(164, 164).T
u2 = scipy.sparse.linalg.lsqr(A, v, damp=3, iter_lim=1000)[0]
img2 = u2.reshape(164, 164).T
u3 = scipy.sparse.linalg.lsqr(A, v, damp=5, iter_lim=1000)[0]
img3 = u3.reshape(164, 164).T
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(12, 5))
ax1.imshow(img1, cmap='gray')
ax2.imshow(img2, cmap='gray')
ax3.imshow(img3, cmap='gray')
ax1.set_title('$c=1$')
ax2.set_title('$c=3$')
ax3.set_title('$c=5$')
plt.show()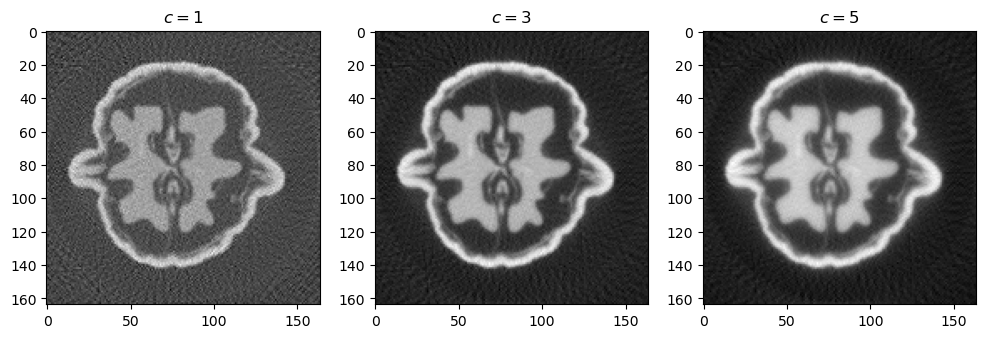
- Shepp, L. A., & Logan, B. F. (1974). The Fourier reconstruction of a head section. IEEE Transactions on Nuclear Science, 21(3), 21–43. 10.1109/tns.1974.6499235