Lineare Regression#
Hier betrachten wir folgende Situation: Es liegt eine 2-dimensionale Stichprobe zweier metrischer Merkmale vor
Diese lassen sich als Punkte in einem 2-dimensionalen Streudiagramm plotten. Wir fragen uns nun welche Gerade approximiert diese Punkte am besten? Dabei sind 2 Fragen zu klären:
Was bedeutet „approximiert … am besten“?
Wie finden wir eine solche /diese Gerade?
Kleine Quadrate#
Gute Approximation der Punkte durch eine Gerade soll bedeuten, dass die vertikalen Abstände der Gerade zu den Punkten möglichst klein sein sollen. Schauen wir uns in einer Grafik an was da bedeutet:
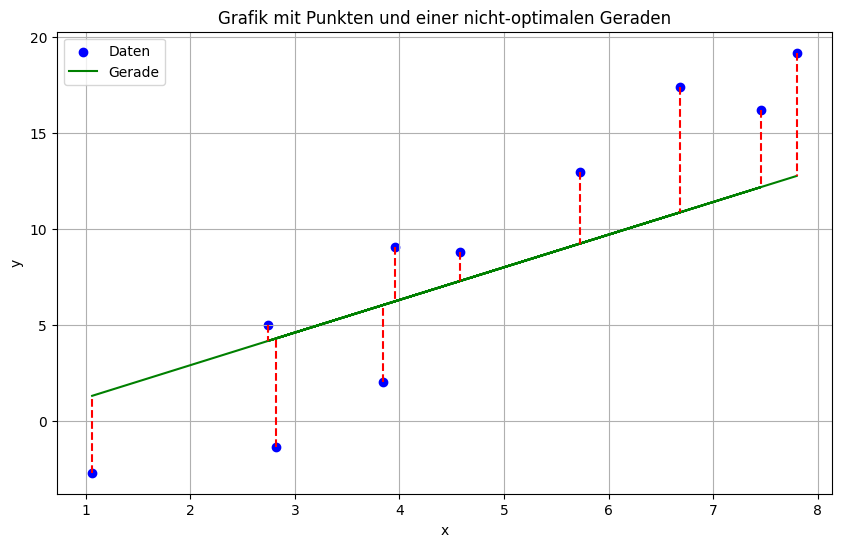
Wir erkennen: Wenn die gerade etwas steiler wäre, würde viele der roten Linien kürzer sein. Die Gerade würde dann besser zu den Daten passen. Da wir wollen das alle roten Linie möglichst kurz sind, brauchen wir ein Kriterium, das alle gleichzeit betrachtet. Dieses lautet wie folgt:
Die Summe der Quadrate der Längen der roten Linien soll minimal sein
In der nächsten Definition schreiben wir dies als Formel auf und definieren so die Regressionsgerade.
Definition
Es seien die Punkte \( (x_1,y_1), (x_2,y_2), \dots, (x_n,y_n) \) gegeben. Sind \(m\) und \(n\) so gewählt, dass
minimal ist, nennen wir die Gerade \(y=mx+n\) Regressionsgerade (oder Ausgleichsgerade oder Trendlinie) zu den Datenpunkten.
Schauen wir uns noch einmal die Geradengleichung an: \(y=mx+n\). Hier ist \(y\) eine Funktion von \(x\). Anders ausgedrückt, \(y\) hängt von \(x\) ab. In der Statistik sagt man dann auch \(y\) wird durch \(x\) erklärt. Dementsprechend verwendet man die Bezeichnungen:
\(y\) … Zielvariable / zu erklärende Variable / abhängige Variable
\(x\) … Regressor / erklärende Variable / unabhängige Variable
Achtung
Mit Hilfe der Regressionsgeraden wird die Zielvariable \(y\) in Abhängigkeit der erklärenden Variable \(x\) beschrieben. Es wird damit also modelliert, wie sich \(y\) verändert, wenn sich \(x\) verändert. Wichtig ist dabei die Rollenverteilung der Variablen: \(y\) ist die zu erklärende oder vorherzusagende Größe, \(x\) ist die erklärende Größe. Diese Rollen können nicht beliebig vertauscht werden. Welche Variable als \(x\) und welche als \(y\) verwendet wird, hängt von der inhaltlichen Fragestellung ab. Möchte man zum Beispiel den Preis einer Wohnung durch ihre Wohnfläche erklären, ist die Wohnfläche die erklärende Variable \(x\) und der Preis die Zielvariable \(y\).
Mathematisch gesehen ist das suchen einer Regressionsgeraden ein Optimierungsproblem. Es ist eine Funktion zu minimieren, die von 2 Variablen (\(m\) und \(n\)) abhängt.
Bevor wir uns ansehen, wie die Lösungs dieses Optimierungsproblems aussieht, schauen wir uns das in einem interaktiven Plot an. Dort sehen wir:
Punkte die sich hin und her schieben lassen.
eine Gerade die wir mitte den beiden blauen Punkten bewegen können
Klick auf „vertikale Abstände“ zeichnet die zu minimierenden Abstände ein
Klick auf „Abstandsquadrate“ zeichnet den aktuellen Wert der zu minimierende Summe (siehe Definition) ein.
Klick auf „Trendlinie“ zeichnet die optimale Gerade, also die Regressionsgerade ein
Hinweis: Klick auf „Abstand“ zeichet die orthogonalen Abstand der Punkte zur Geraden ein. Dieser wird bei der Regressionsgeraden zwar auch sehr klein. Es ist jedoch nicht das Ziel diesen Abstand zu minimieren.
Wir suchen also diejenige Gerade, für welche die Quadrate am kleinsten werden. Aus diesem Grund nennt man dies auch die Methode der kleinsten Quadrate. Wir haben dieses Prinzip hier in seiner einfachsten Variante kennengelernt.
Hinter dem Tellerrand ..
Die Methode der kleinsten Quadrate (Least Squares Method) ist ein fundamentales Verfahren in der Statistik zur Anpassung von Modellen an Daten. Sie wurde erstmals von Carl Friedrich Gauß (1777–1855) im frühen 19. Jahrhundert beschrieben.
Das Prinzip der kleinsten Quadrate basiert darauf, die Summe der quadrierten Abweichungen zwischen den beobachteten Werten und den durch das Modell vorhergesagten Werten zu minimieren. Diese Methode ermöglicht es, bespielsweise eine sogenannte Regressionsgerade zu bestimmen, die den linearen Zusammenhang zwischen zwei Variablen bestmöglich beschreibt.
Gauß entwickelte die Methode im Zusammenhang mit astronomischen Beobachtungen, um die Umlaufbahn des neu entdeckten Planeten Ceres zu berechnen. Seine Arbeiten trugen maßgeblich zur Verbreitung der Methode in den Naturwissenschaften bei.
Heute ist die Methode der kleinsten Quadrate ein zentrales Verfahren in der Statistik, Ökonomie und vielen weiteren Disziplinen, um lineare und nichtlineare Modelle an empirische Daten anzupassen.
Formeln zur Berechnung#
Nun wollen wir zeigen, wie die optimalen Größen \(m\) und \(n\) berechnet werden.
Satz
Es seien die Punkte \( (x_1,y_1), (x_2,y_2), \dots, (x_n,y_n) \) gegeben. Die Konstanten \(m\) und \(n\) der zugehörigen Regressionsgeraden \(y=mx+n\) berechnen sich wie folgt:
wobei \(\bar x\) und \(\bar y\) die Mittelwerte, \(s_x\) und \(s_y\) die Standardabweichungen der Stichproben \(x_1,\dots,x_n\) bzw. \(y_1,\dots,y_n\) sind und \(r_{xy}\) der Stichproben-Korrelationskoeffizient ist.
Um zu bewerten, wie gut die Regressiongerade zu den Daten passt, nutzt man gern das sogenannte Bestimmtheitsmaß \(R^2\) (R-Quadrat). Man berechnet es hier einfach indem man den Korrelationskoeffizienten quadriert:
Es gilt steht \(0\leq R^2 \leq 1\).
Interpretation
\(R^2 = 1\): perfekter linearer Zusammenhang, alle Daten liegen auf einer Geraden
\(R^2 = 0\): kein linearer Zusammenhang
\(R^2\) nahe \(1\): es liegt ein starker linearer Zusammenhang vor
\(R^2\) nahe \(0\): es liegt nahezu kein linearer Zusammenhang vor
Man sagt: \(R^2\) ist gleich dem Anteil der durch das Modell erklärten Variation in den \(y\)-Werten.
Auf genauere Erklärungen hierzu verzichten wir an dieser Stelle.
Beispiel#
Bevor wir lernen wie das in R berechen wird, wollen wir uns an einem Mini-Beispiel anschauen wie wir die Regressionsgerade per Hand berechnen.
Beispiel
Gegeben seien die fünf Punkte:
Wir wollen die Regressionsgerade der Form
berechnen.
1. Schritt: Mittelwerte berechnen
Die Mittelwerte \(\bar x\) und \(\bar y\) ergeben sich aus:
2. Schritt: Standardabweichungen berechnen
Die Standardabweichungen \(s_x\) und \(s_y\) berechnen sich als:
3. Schritt: Korrelationskoeffizient berechnen
Der Stichproben-Korrelationskoeffizient \(r_{xy}\) berechnet sich laut Kapitel Maßzahlen durch:
Die Einzelwerte sind:
Daher gilt:
4. Schritt: Steigung \(m\) und Achsenabschnitt \(n\) berechnen
Für die Steigung \(m\) ergibt sich:
Der Achsenabschnitt \(n\) lautet:
Ergebnis: Die Regressionsgerade lautet
Das Bestimmtheitsmaß beträgt
Prädiktion mit einer Regressionsgeraden#
Eine Regressionsgerade lässt sich nicht nur zur Beschreibung eines Zusammenhangs zwischen zwei Variablen nutzen, sondern auch zur Vorhersage neuer Werte. Hat man für einen neuen Wert der unabhängigen Variable \(x\) (Prädiktor) noch keinen zugehörigen \(y\)-Wert beobachtet, kann die Regressionsgerade verwendet werden, um den erwarteten Wert \(\hat{y}\) vorherzusagen.
Dabei ist jedoch zu beachten, dass es sich nur um eine Schätzung handelt. Wie zuverlässig die Vorhersage ist, hängt stark davon ab, wie gut die Regressionsgerade die Daten beschreibt. Ein kleines Bestimmtheitsmaß \(R^2\) deutet darauf hin, dass nur ein geringer Anteil der Variation in den Daten durch das Modell erklärt wird – die Vorhersagen sind dann entsprechend unsicher.
Besonders vorsichtig sollte man bei Extrapolationen sein, also wenn man Vorhersagen für \(x\)-Werte außerhalb des beobachteten Bereichs trifft. In solchen Fällen verlässt man sich auf die Annahme, dass der lineare Zusammenhang auch außerhalb der bekannten Daten gilt – was in der Praxis oft nicht der Fall ist.