Konzentrationsmaße#
Was soll gemessen werden?#
Ein Konzentrationsmaß misst, wie ungleich eine bestimmte Größe (z. B. Einkommen, Marktanteile oder Bevölkerung) innerhalb einer Gruppe verteilt ist. Es zeigt also, ob eine Ressource stark konzentriert oder gleichmäßig verteilt ist.
Beispiele#
Einkommensverteilung:
Wenn in einer Stadt 100 Menschen leben und jeder genau 2.000 € im Monat verdient, ist die Verteilung gleichmäßig – die Konzentration ist niedrig.
Wenn aber ein Mensch 100.000 € hat und die anderen 99 nur je 500 €, dann ist die Konzentration hoch, weil wenige viel besitzen und viele wenig.
Marktanteile:
Wenn zehn Firmen jeweils 10 % des Marktes kontrollieren, ist die Konzentration gering.
Wenn aber eine Firma 91 % und die anderen neun je nur 1 % haben, ist der Markt stark konzentriert (Monopol-Tendenz).
Bevölkerungsverteilung in Städten:
Wenn ein Land nur aus Städten besteht mit etwa der gleichen Eingwohnerzahl, ist die Bevölkerung gleichmäßig verteilt (niedrige Konzentration).
Wenn fast alle Menschen in einer einzigen Mega-Stadt leben und der Rest des Landes dünn besiedelt ist, ist die Konzentration hoch.
Um diese Art von Konzentration in Zahlen zu fassen lernen wir hier 2 Maßzahlen kennen:
den Gini-Koeffizient
den Herfindahl-Index
Außerdem werden wir eine graphische Visualisierung der Konzentration kennenlernen, die Lorenzkurve.
Lorenzkurve#
Hier gehen wir davon aus, dass die Daten in Form einer geordneten Liste
aus nicht-negativen Werten vorliegen. Die Lorenzkurve visualisiert - für jedes k - welchen Anteil die \(k\) kleinsten Wert an der Gesamtsumme haben, also für \(1\leq k\leq n\)
Definition
Zu einer gegebenen Liste \( x_1 \leq x_2 \leq \dots \leq x_n \) aus nicht-negativen Zahlen heißt der Streckenzug durch die Punkte
Lorenzkurve, wobei
Stellen wir uns vor \(x_1,\dots,x_n\) beschreibt die Marktanteile von \(n\) Unternehmen. Der Gesamtmarkt habe die Größe \(x_1+\dots+x_n\). Dann ist
\(u_k\) der Anteil \(k\) kleinsten Marktteilnehmer
\(v_k\) der kummulierte Marktanteil für die \(k\) kleinsten Marktteilnehmer
Beispiel
Angenommen, wir haben 5 Haushalte mit folgendem monatlichen Einkommen (in Euro):
Haushalt |
Einkommen (in Euro) |
|---|---|
A |
\(4000\) |
B |
\(2000\) |
C |
\(1000\) |
D |
\(3000\) |
E |
\(10000\) |
Zuerst ordnen wir die Stichprobe:
Das Gesamteinkommen beträgt:
Die Berechnung der \(u_k\) und \(v_k\):
Index \(k\) |
\(u_k\) |
Einkommen (sortiert) |
Anteil am Ges.Einkommen |
\(v_k\) |
|---|---|---|---|---|
\(1\) |
\(\frac15=0.2\) |
\(1000\) |
\(\frac{1}{20}\) |
\(\frac{1}{20}=0.05\) |
\(2\) |
\(\frac25=0.4\) |
\(2000\) |
\(\frac{2}{20}\) |
\(\frac{3}{20}=0.15\) |
\(3\) |
\(\frac35=0.6\) |
\(3000\) |
\(\frac{3}{20}\) |
\(\frac{6}{20}=0.3\) |
\(4\) |
\(\frac45=0.8\) |
\(4000\) |
\(\frac{4}{20}\) |
\(\frac{10}{20}=0.5\) |
\(5\) |
\(\frac55=1\) |
\(10000\) |
\(\frac{10}{20}\) |
\(\frac{20}{20}=1\) |
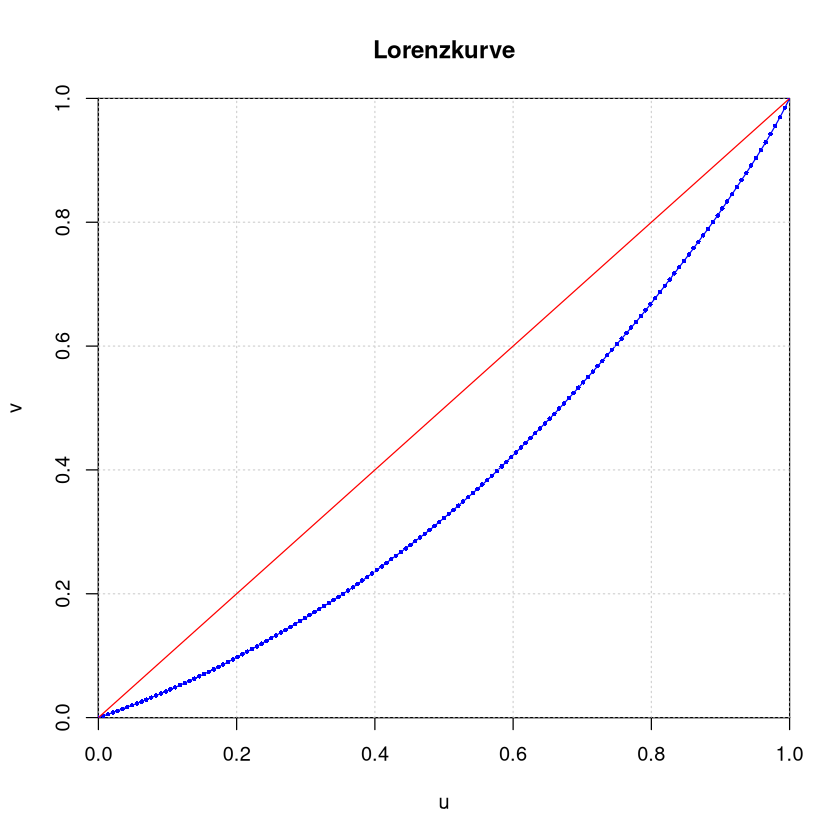
Die Lorenzkurve verläuft also durch die Punkte
Im folgenden R-Code wird diese Lorenzkurve erstellt.
Umsetzung in R#
# Einkommenswerte (aufsteigend sortiert)
einkommen <- c(1000, 2000, 3000, 4000, 10000)
n <- length(einkommen) # Stichprobengröße
u <- (0:n)/n # u-Vektor
f <- einkommen/sum(einkommen) # Anteil des Gesamteinkommens
v <- c(0,cumsum(f)) # kummulierter Anteil des Gesamteinkommens
rbind(u,v) # klebt u und v zu Matrix zusammen
# Plot-Befehle:
plot(u,v, type="l", xlim=c(0,1), ylim=c(0,1), xaxs="i", yaxs="i", col="blue", main="Lorenzkurve") # Lorenzkurve
grid() # Gitter
points(u, v, pch=16, col="blue") # Punkte an den Knicken hinzufügen
abline(0,1, col="red") # Diagonale
| u | 0 | 0.20 | 0.40 | 0.6 | 0.8 | 1 |
|---|---|---|---|---|---|---|
| v | 0 | 0.05 | 0.15 | 0.3 | 0.5 | 1 |
Erläuterung des R-Codes#
einkommen <- c(1000, 2000, 3000, 4000, 10000)Erstellt einen Vektor einkommen, der die Einkommen von 5 Haushalten speichert.
Die Werte sind aufsteigend sortiert, was für die Lorenzkurve wichtig ist.
Sind die Werte noch nicht sortiert, nutze
sort().
n <- length(einkommen)Dies zählt die Anzahl der Elemente im Vektor (hier n = 5).
u <- (0:n)Erstellt den Vektor u, der die kumulierten Anteile der Haushalte darstellt.
0:nerzeugt eine Zahlenreihe von 0 bis n (also 0, 1, 2, 3, 4, 5).Durch Teilen durch n wird das Ganze in ein Zahl zwischen 0 und 1t umgewandelt: u = (0, 0.2, 0.4, 0.6, 0.8, 1).
ant.eink <- einkommen / sum(einkommen)sum(einkommen)berechnet das gesamte Einkommen (1000 + 2000 + 3000 + 4000 + 10000 = 20000).Jedes Einkommen wird durch diese Summe geteilt. Dies ergibt den prozentualen Anteil jedes Haushalts am Gesamteinkommen.
v <- c(0, cumsum(f))cumsum(f)berechnet die kumulierte Summe der Anteilec(0, ...)setzt am Anfang eine 0, damit die Lorenzkurve immer bei (0,0) beginnt. Für den Vektor u haben wir die Null oben auch schon erzeugt.Ergebnis: v = (0, 0.05, 0.15, 0.3, 0.5, 1)
rbind(u,v)Dies erzeugt eine Matrix, in der die beiden Vektoren untereinander stehen.
So kann man beide Werte direkt nebeneinander sehen.
plot(u, v, type="l", xlim=c(0,1), ylim=c(0,1), xaxs="i", yaxs="i", col="blue", main="Lorenzkurve")plot(u, v, type="l")zeichnet eine Linie (type="l") basierend auf den u- und v-Werten.xlim=c(0,1), ylim=c(0,1)begrenzen die Achsen exakt auf das Intervall \([0,1]\).xaxs="i", yaxs="i"entfernt extra Platz an den Rändern.col="blue"zeichnet die Lorenzkurve in blau.main="Lorenzkurve"legt den Titel der Grafik fest
grid()Fügt ein Hintergrund-Gitter hinzu, um die Werte leichter abzulesen.
points(u, v, pch=16, col="blue")setzt blaue Punkte an die Stützstellen der Lorenzkurve.
pch=16bedeutet gefüllte Kreise.
abline(0,1, col="red")zeichnet die Diagonale von (0,0) nach (1,1).
Diese Linie stellt die perfekte Gleichverteilung dar – alle Haushalte hätten den gleichen Anteil am Einkommen.
col="red"macht die Linie rot zur besseren Sichtbarkeit.
Bemerkungen zur Lorenzkurve#
In einem Punkt der Lorenzkurve wird dargestellt, welchen Markanteil die kleinsten Marktteilnehmer für sich beanspruchen. Wird z.B. der Punkt \((0.4,0.15)\) in der Kurve abgetragen, so heißt dies: Die \(40\%\) kleinsten Marktteilnehmer besitzen zusammen \(15\%\) des gesamten Marktanteils.
Die Lorenzkurve liegt genau dann auf der Diagonalen (d.h. auf der Geraden \(u=v\)), wenn der gesamte Markt gleichmäßig unter den Teilnehmener aufgeteilt ist.
Je weiter sich die Lorenzkurve „in die Ecke schmiegt“, desto stärker ist die Konzentration der Marktanteile bei wenigen Marktteilnehmern (d.h. desto ungleichmäßiger sind die Anteile verteilt).
Um die Stärke der Konzentration zu quantifizieren, berechnen wir die Fläche zwischen der Lorenzkurve und der Diagonalen. Dies führt zum Gini-Koeffizient, siehe nächstes Kapitel.
große Fläche \(\Rightarrow\) starke Konzentration
kleine Fläche \(\Rightarrow\) geringe Konzentration
Gini-Koeffizient#
Definition
Ist die geordnete Stichprobe \(x_{1}, \dots ,x_{n}\) gegeben, so gilt berechnet sich der Gini-Koeffizient mittels:
Der Gini-Koeffizient entspricht genau dem Verhältznis zwischen Fläche zwischen Diagonale und Lorenzkurve und Fläche zwischen Diagonale und \(u\)-Achse, also
Häufigkeiten#
Ist die Stichprobe mit Häufigkeiten gegeben, so gibt es (ähnlich wie bei Mittelwert und Standardabweichung) eine effizientere Methode den Gini-Koeffizient zu berechnen:
Sind die geordneten Ausprägungen \(a_1<\dots< a_k\) und die zugehörigen Häufigkeiten \(h_1,\dots,h_k\) gegeben:
wobei
Bemerkungen zum Gini-Koeffizient#
Gilt \(x_1=\dots=x_n\), so ergibt sich \(G=0\) (Nullkonzentration)
Gilt \(x_1=\dots=x_{n-1}=0\) und \(x_n\neq 0\), so gilt \(G=\frac{n-1}{n}\) (maximale Konzentration)
Folgerung: es gilt immer \(0\leq G \leq \frac{n-1}{n}\)
Damit der Gini-Koeffizient bei maximaler Konzentration den Wert 1 annimmt, verwendet man gern den normierten Gini-Koeffizient
Definition
Der normierte Gini-Koeffizient ergibt sich mittls
Folgerung: es gilt immer \(0\leq G^* \leq 1\)
Beachte: Es kann trotz gleichem Gini-Koeffizient eine unterschiedliche Verteilung der Anteile vorliegen.
Umsetzung in R#
stichprobe <- c(4,2,5,9,1,3,3,4)
x <- sort(stichprobe)
n <- length(stichprobe)
G <- ( 2*sum(x * (1:n)) ) / ( n * sum(x) ) - (n+1)/n
Gnorm <- G * n / (n-1)
cat("Gini-Koeffizient: ",G,"\n\n")
cat("normierter Gini-Koeffizient: ",Gnorm,"\n\n")
Gini-Koeffizient: 0.3024194
normierter Gini-Koeffizient: 0.3456221
Herfindahl-Index#
In diesem Kapitel folgt eine weitere Methode um die Konzentration zu messen
Wir stellen uns hier vor die Daten liegen in Form einer Liste
bestehend aus nicht-negativen Werten vor. Der relative Anteil den ein Wert am Gesamten hat ist \(f_i:=\frac{x_i}{x_1+\dots+x_n}\), \(i=1,\dots,n\) also
Definition
Der Herfindahl-Index ist nun definiert als die folgende Quadratsumme der relativen Anteile
Beispiel
In einem fiktiven Land gibt es 5 Städte mit folgenden Einwohnerzahlen
Stadt |
\(\text{A}\) |
\(\text{B}\) |
\(\text{C}\) |
\(\text{D}\) |
\(\text{E}\) |
Einwohnerzahl |
\(5000\) |
\(15000\) |
\(10000\) |
\(20000\) |
\(50000\) |
Die Gesamteinwohnerzahl ist damit
So berechnen sich die Anteil, also die relativen Häufigkeiten mittels
und der Herfindahl-Index
Der Herfindahl-Index liegt bei \(1/n\), wenn \(x_1=\dots=x_n\) also alle Teilnehmer den gleichen Marktanteil haben.
Der Herfindahl-Index liegt bei \(1\), wenn es einen Marktteilnehmer gibt, der einen 100%igen Marktanteil hat, d.h wenn \(x_1=\dots=x_{n-1}=0\) und \(x_n\neq 0\).
Im Allgemeinen gilt: \(\frac1n \leq H \leq 1\)
Je höher der Herfindahl-Index, desto stärker ist die Konzentration
Umsetzung in R#
einwohner <- c(5000,15000,10000,20000,50000)
f <- einwohner/sum(einwohner)
H <- sum(f^2)
cat("Herfindahl-Index: ",H)
Herfindahl-Index: 0.325
Mehr Beispiele#
Wir schauen uns hier noch ein paar Beispiele an.
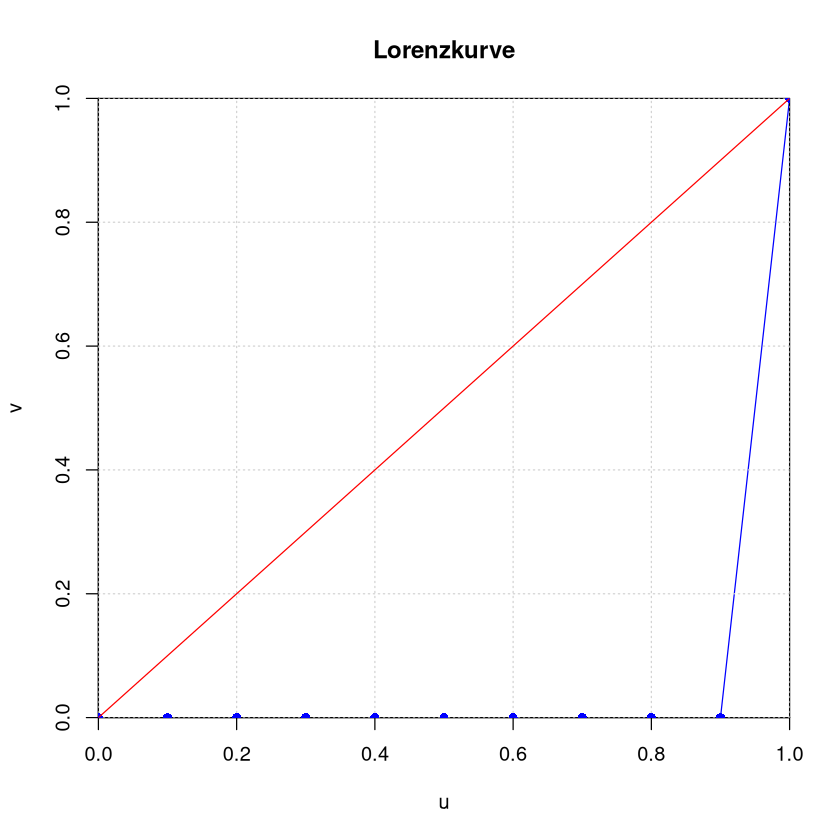
Beispiel: Monopol#
Ein Marktteilnehmer hat alles, alle anderen haben nichts.
x <- c(0,0,0,0,0,0,0,0,0,1)
n <- length(x)
# Gini-Koeffizient
G <- ( 2*sum(x * (1:n)) ) / ( n * sum(x) ) - (n+1)/n
# normierter Gini-Koeffizient
Gnorm <- G * n / (n-1)
# Herfindahl-Index
H <- sum( (x/sum(x))^2 )
cat("Gini-Koeffizient: ",G,"\n\n")
cat("normierter Gini-Koeffizient: ",Gnorm,"\n\n")
cat("Herfindahl-Index: ",H,"\n\n")
u <- (0:n)/n # u-Vektor
f <- x/sum(x)
v <- c(0,cumsum(f)) # kummulierter Anteil der Gesamtsumme
rbind(u,v) # klebt u und v zu Matrix zusammen
# Plot-Befehle:
plot(u,v, type="l", xlim=c(0,1), ylim=c(0,1), xaxs="i", yaxs="i", col="blue", main="Lorenzkurve") # Lorenzkurve
grid() # Gitter
points(u, v, pch=16, col="blue") # Punkte an den Knicken hinzufügen
abline(0,1, col="red") # Diagonale
Gini-Koeffizient: 0.9
normierter Gini-Koeffizient: 1
Herfindahl-Index: 1
| u | 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| v | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1 |
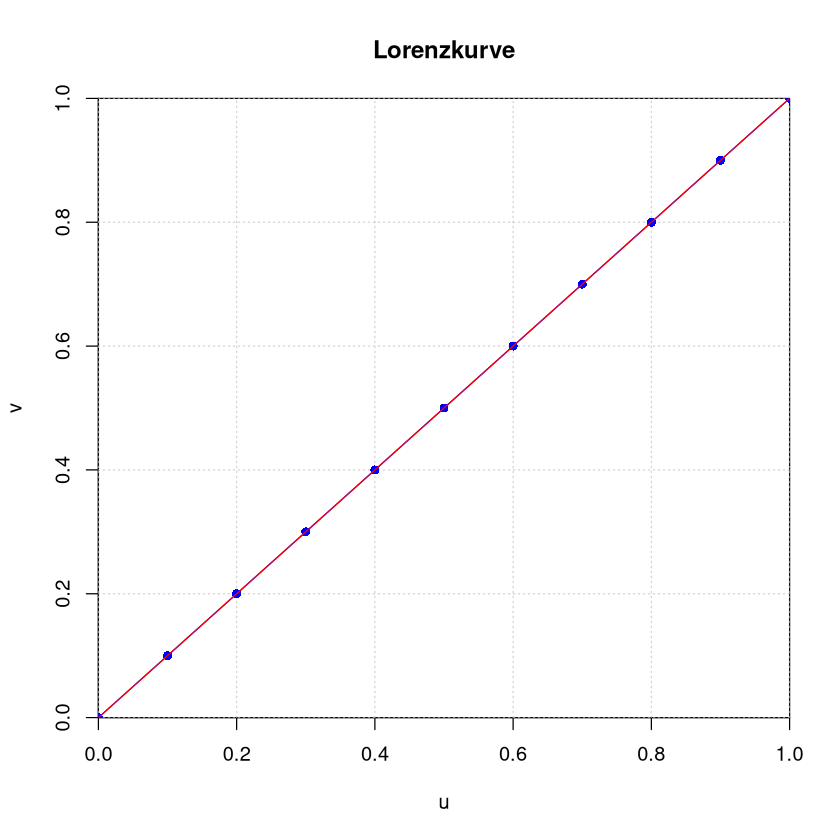
Beispiel: Nullkonzentration#
Alle Marktteilnehmer haben den gleichen Anteil am Markt.
x <- c(5,5,5,5,5,5,5,5,5,5)
n <- length(x)
# Gini-Koeffizient
G <- ( 2*sum(x * (1:n)) ) / ( n * sum(x) ) - (n+1)/n
# normierter Gini-Koeffizient
Gnorm <- G * n / (n-1)
# Herfindahl-Index
H <- sum( (x/sum(x))^2 )
cat("Gini-Koeffizient: ",G,"\n\n")
cat("normierter Gini-Koeffizient: ",Gnorm,"\n\n")
cat("Herfindahl-Index: ",H,"\n\n")
u <- (0:n)/n # u-Vektor
f <- x/sum(x)
v <- c(0,cumsum(f)) # kummulierter Anteil der Gesamtsumme
rbind(u,v) # klebt u und v zu Matrix zusammen
# Plot-Befehle:
plot(u,v, type="l", xlim=c(0,1), ylim=c(0,1), xaxs="i", yaxs="i", col="blue", main="Lorenzkurve") # Lorenzkurve
grid() # Gitter
points(u, v, pch=16, col="blue") # Punkte an den Knicken hinzufügen
abline(0,1, col="red") # Diagonale
Gini-Koeffizient: 0
normierter Gini-Koeffizient: 0
Herfindahl-Index: 0.1
| u | 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| v | 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1 |
Beispiel: Mittlere Konzentration, reale Daten#
Monatliche Passagierzahlen für internationale Flüge von 1949 bis 1960. Mehr Informationen dazu mit der Eingabe help(AirPassengers) in R.
x <- sort(as.numeric(AirPassengers))
cat("Die sortieren Daten: ")
x
n <- length(x)
# Gini-Koeffizient
G <- ( 2*sum(x * (1:n)) ) / ( n * sum(x) ) - (n+1)/n
# normierter Gini-Koeffizient
Gnorm <- G * n / (n-1)
# Herfindahl-Index
H <- sum( (x/sum(x))^2 )
cat("Gini-Koeffizient: ",G,"\n\n")
cat("normierter Gini-Koeffizient: ",Gnorm,"\n\n")
cat("Herfindahl-Index: ",H,"\n\n")
u <- (0:n)/n # u-Vektor
f <- x/sum(x)
v <- c(0,cumsum(f)) # kummulierter Anteil der Gesamtsumme
rbind(u,v) # klebt u und v zu Matrix zusammen
# Plot-Befehle:
plot(u,v, type="l", xlim=c(0,1), ylim=c(0,1), xaxs="i", yaxs="i", col="blue", main="Lorenzkurve") # Lorenzkurve
grid() # Gitter
points(u, v, pch=16, col="blue", cex=0.5) # Punkte an den Knicken hinzufügen
abline(0,1, col="red") # Diagonale
Die sortieren Daten:
- 104
- 112
- 114
- 115
- 118
- 118
- 119
- 121
- 125
- 126
- 129
- 132
- 133
- 135
- 135
- 136
- 140
- 141
- 145
- 146
- 148
- 148
- 149
- 150
- 158
- 162
- 163
- 166
- 170
- 170
- 171
- 172
- 172
- 178
- 178
- 180
- 180
- 181
- 183
- 184
- 188
- 191
- 193
- 194
- 196
- 196
- 199
- 199
- 201
- 203
- 204
- 209
- 211
- 218
- 227
- 229
- 229
- 229
- 230
- 233
- 234
- 235
- 235
- 236
- 237
- 237
- 242
- 242
- 243
- 259
- 264
- 264
- 267
- 269
- 270
- 271
- 272
- 274
- 277
- 278
- 284
- 293
- 301
- 302
- 305
- 306
- 306
- 310
- 312
- 313
- 315
- 315
- 317
- 318
- 318
- 336
- 337
- 340
- 342
- 347
- 347
- 348
- 348
- 355
- 355
- 356
- 359
- 360
- 362
- 362
- 363
- 364
- 374
- 390
- 391
- 396
- 404
- 404
- 405
- 405
- 406
- 407
- 413
- 417
- 419
- 420
- 422
- 432
- 435
- 461
- 461
- 463
- 465
- 467
- 472
- 472
- 491
- 505
- 508
- 535
- 548
- 559
- 606
- 622
Gini-Koeffizient: 0.2407563
normierter Gini-Koeffizient: 0.2424399
Herfindahl-Index: 0.00820769
| u | 0 | 0.006944444 | 0.013888889 | 0.020833333 | 0.02777778 | 0.03472222 | 0.04166667 | 0.04861111 | 0.05555556 | 0.06250000 | ⋯ | 0.9375000 | 0.9444444 | 0.9513889 | 0.9583333 | 0.9652778 | 0.9722222 | 0.9791667 | 0.9861111 | 0.9930556 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| v | 0 | 0.002576617 | 0.005351436 | 0.008175805 | 0.01102495 | 0.01394842 | 0.01687189 | 0.01982013 | 0.02281793 | 0.02591482 | ⋯ | 0.8799395 | 0.8916334 | 0.9037980 | 0.9163095 | 0.9288953 | 0.9421500 | 0.9557268 | 0.9695761 | 0.9845898 | 1 |